Bounded sequences in can fail to have convergent subsequences in two ways: oscillation (mass escaping to high frequencies) and translation (mass escaping to spatial infinity). Controlling a derivative kills oscillation; working on a bounded domain kills translation. Together they restore Bolzano-Weierstrass. This is Rellich-Kondrachov compactness.
Along the way, controlling derivatives also upgrades integrability. The Sobolev embedding theorem makes this quantitative: derivatives in buy integrability up to (or continuity if ), with exchange rate set by an uncertainty principle.
Motivation: when does a bounded sequence converge?¶
In finite dimensions, Bolzano-Weierstrass guarantees that every bounded sequence has a convergent subsequence. In infinite-dimensional spaces like this fails dramatically, and understanding how it fails is the key to the whole chapter.
Consider a bounded sequence , say . What can go wrong? There are essentially two pathologies:
(P1) Oscillation, where energy escapes to high frequencies. Take and . Each has , but any two distinct terms are orthogonal, so for . No subsequence is Cauchy. The mass does not escape in space; instead it escapes into ever higher frequencies.
(P2) Translation, where energy escapes to spatial infinity. On , fix a bump with and set . Each has norm 1, but the supports become disjoint, so again . The mass slides off to infinity.
These two examples exhaust the ways compactness can fail in : any non-precompact bounded sequence is, up to subsequence, a combination of oscillating modes and escaping bumps. The whole chapter can be read as a program to defeat these two pathologies and recover Bolzano-Weierstrass:
Kill oscillation by controlling a derivative. If is also bounded, the high Fourier modes cannot carry the mass. The derivative of has norm , which blows up, so controlling the gradient caps the usable frequency.
Kill translation by working on a bounded domain, where there is nowhere for the mass to escape to.
Doing both yields Rellich-Kondrachov compactness: the embedding is compact on bounded . Along the way we will also see how controlling derivatives not only rescues compactness but upgrades integrability, climbing the ladder toward and Hölder continuity. This is the Sobolev embedding theorem.
From Sobolev regularity to integrability¶
The Sobolev norm controls more than just derivatives; it forces the function to have better integrability and even continuity, depending on how many derivatives are controlled.
Before making this quantitative, it is worth asking why we want integrability control at all. The answer points to a single goal: we are trying to climb the ladder
because the top of the ladder is where classical tools live. Continuous and equicontinuous functions are precompact by Arzelà-Ascoli (Theorem 1); continuity lets us evaluate at a point, impose classical boundary values, and make sense of nonlinear terms like pointwise. The rungs in between are what we settle for when we cannot reach the top. The Sobolev embedding theorem tells us exactly how high we can climb given a fixed budget of derivatives.
The simplest instance is the Poincaré inequality, which in one dimension turns out to climb all the way.
The Poincaré inequality: the prototype embedding¶
Everything in the Sobolev embedding theorem can be read off a single one-dimensional calculation. We do that calculation here, and the result is the prototype: a single pointwise estimate, obtained from the fundamental theorem of calculus and Cauchy-Schwarz, produces three regularity statements at once,
Every higher-dimensional Sobolev embedding is a way of running this same template in directions.
The single estimate. Take and , so . The fundamental theorem of calculus gives the representation , and Cauchy-Schwarz turns it into a pointwise bound:
(Strictly speaking, the FTC representation holds pointwise for with ; the estimate then extends to all of by density, and simultaneously shows that each has a continuous representative for which holds.)
That is the engine. The three regularity statements all fall out by reading in different ways.
Rung 1: control (the Poincaré inequality). Integrate in over :
The gradient controls the function in mean square.
Rung 2: control. Take the supremum over in :
The gradient controls the function pointwise.
Rung 3: Hölder control. Apply the same Cauchy-Schwarz argument to the difference :
so with seminorm bounded by . The gradient controls the function’s continuity.
Three regularity classes, one estimate. The classical Poincaré inequality is just rung 1, and we record it formally.
Theorem 1 (Poincaré inequality on )
Let be a bounded, connected open set with Lipschitz boundary. There exists a constant such that for all ,
In one dimension this trade is lossless: a single derivative in buys all the way to Hölder continuity, the top of the integrability ladder. Rellich compactness then comes for free, since a bounded set in is uniformly bounded and equicontinuous, and Arzelà-Ascoli (Theorem 1) delivers a -convergent subsequence. The motivating oscillation pathology is automatically excluded: its norm blows up, so never enters the bounded ball in the first place.
The variance picture¶
The rung has a probabilistic flavor: is the variance of around its mean, summed in squared sense. The plot below shows a typical function on with its mean line; each arrow has length , and the squared sum of all arrows is . Poincaré says this total cannot exceed : a flatter function (small gradient) means short arrows, hence small variance.
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0, 1, 400)
u = np.sin(np.pi * x) + 0.3 * np.sin(3 * np.pi * x)
u_mean = np.trapezoid(u, x)
fig, ax = plt.subplots(figsize=(8, 4.5))
ax.plot(x, u, 'C0', lw=2, label=r'$u(x)$, $u \in H^1_0(0,1)$')
ax.axhline(u_mean, color='C3', lw=1.6, ls='--', label=fr'$\bar u \approx {u_mean:.2f}$')
ax.axhline(0, color='gray', lw=0.6)
sample_x = np.linspace(0.05, 0.95, 17)
sample_u = np.interp(sample_x, x, u)
for sx, su in zip(sample_x, sample_u):
color = 'C2' if su >= u_mean else 'C1'
ax.annotate('', xy=(sx, su), xytext=(sx, u_mean),
arrowprops=dict(arrowstyle='->', color=color, lw=1.0, alpha=0.85))
ax.fill_between(x, u, u_mean, where=(u >= u_mean),
color='C2', alpha=0.12, label=r'$u(x) > \bar u$')
ax.fill_between(x, u, u_mean, where=(u < u_mean),
color='C1', alpha=0.12, label=r'$u(x) < \bar u$')
ax.set_xlabel('$x$')
ax.set_ylabel('value')
ax.set_xlim(0, 1)
ax.set_title(r'Variance picture: residual $u(x) - \bar u$ summed in squared $L^2$',
fontsize=11)
ax.legend(loc='lower center', ncol=2, fontsize=9, framealpha=0.95)
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()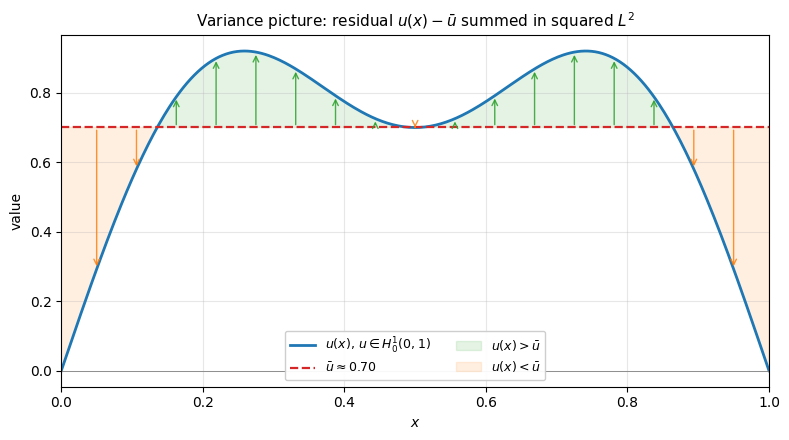
The statement of Poincaré bounds rather than just , and the mean does not appear. This is sometimes called “the mean drops out,” but it deserves a careful reading. The Pythagorean decomposition
splits the squared norm into orthogonal pieces. On all of , the gradient controls only the variance: a constant function has but arbitrary mean. On , the boundary condition forces back to zero at , so a small gradient also prevents the function from sitting at a high plateau; the mean energy is itself bounded by the gradient. Indeed, FTC with and Cauchy-Schwarz give pointwise, so and thus — no appeal to Poincaré needed. Both orthogonal pieces are then controlled, and they combine into the cleaner . The mean is not made zero (a typical function has ); the boundary condition has just made it controllable in the same breath as the variance.
Remark 1 (The mean-free Poincaré-Wirtinger version on )
Without a boundary condition, the gradient cannot detect constants (), so any inequality of the form fails on . The fix is to subtract the mean,
which projects onto the orthogonal complement of constants where is injective. This is the Poincaré-Wirtinger inequality. Its proof requires a different technique (typically compactness and contradiction); the FTC argument above does not extend. We do not use this version in this chapter.
The frequency picture as confirmation¶
The same ladder appears in Fourier coordinates. On with zero boundary, the eigenfunctions of are with eigenvalues . These form an orthogonal basis of and the same family, suitably normalized by , is an orthogonal basis of . So for we may write with convergence in both and , and
Rung 1: control (Poincaré). Term by term the coefficient inequality is immediate (since ), and summing in gives Poincaré:
The optimal constant is attained by the lowest mode , the slowest-oscillating eigenfunction.
Rung 2: control. Bound the series pointwise by its coefficients and apply Cauchy-Schwarz on the index :
The convergent sum is what makes the bound finite, and it is exactly the Fourier shadow of the step in .
Rung 3: Hölder control. Expand the difference and use termwise, then Cauchy-Schwarz:
Split the last sum at the crossover where the two arguments of cross. Low-frequency modes ( below the crossover) are still in the smooth regime , so they contribute the -factor; high-frequency modes ( above the crossover) oscillate too fast to resolve the displacement , so only the crude bound 2 is available. Balancing the two halves gives the exponent.
So all three rungs are visible in Fourier, each as a different way of weighting against a convergent geometric factor.
-compactness (Rellich-Kondrachov in 1D). The same expansion delivers -compactness in one line. Let , and let be the projection onto the first modes. Then lives in the finite-dimensional (hence precompact) subspace , while the tail is uniformly small in :
So is totally bounded in (covered by finitely many balls of any prescribed radius, using ’s own compactness for the head), hence precompact. This is Rellich-Kondrachov in 1D.
The same ball is also equicontinuous in by the Hölder rung ( uniformly in ), so Arzelà-Ascoli gives uniform-norm precompactness — and upgrades this to -precompactness too. The two proofs are the same phenomenon seen twice: high-frequency modes decay and uniform equicontinuity are dual descriptions of “the bounded ball has no room to escape to infinity in .”
The uncertainty principle and the general theorem¶
The Sobolev embedding theorem says that controlling derivatives in forces membership in with . Where does this critical exponent come from? The answer is an uncertainty principle: a function cannot be simultaneously localized in both space and frequency.
Two regimes of the model function¶
Fix a smooth bump on with support in the unit ball, and a unit vector . The model function is
a bump of height , spatial scale , oscillating at frequency along direction . Its norms scale with the volume of the support:
Its gradient has two competing terms:
The envelope term , from differentiating the bump,
The oscillation term , from differentiating the sine.
Which dominates depends on the relationship between and :
Well-behaved regime: . The oscillation term dominates: . The function completes many oscillations within its support, and derivatives faithfully measure the frequency. The Sobolev norm behaves as the heuristic predicts: .
Ill-behaved regime: . The envelope term dominates: . The function is so narrow that it does not complete even one oscillation. The “frequency” is invisible, and the gradient is controlled by the compression of the bump.
The following plot illustrates both regimes in the 1D slice along direction (so for the picture; the analysis above is in general ).
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(-3, 3, 2000)
def bump(x):
"""Smooth bump function supported on [-1, 1]."""
result = np.zeros_like(x)
mask = np.abs(x) < 1
result[mask] = np.exp(-1 / (1 - x[mask]**2))
return result / np.max(result) # normalize peak to 1
fig, axes = plt.subplots(2, 2, figsize=(10, 6))
# Well-behaved regime: R = 1, N = 20 (R >> 1/N)
R1, N1 = 1.0, 20
f1 = bump(x / R1) * np.sin(N1 * x)
f1_env = bump(x / R1)
axes[0, 0].plot(x, f1, 'C0', lw=0.8)
axes[0, 0].plot(x, f1_env, 'C3', lw=1.2, ls='--', label='envelope $\\phi(x/R)$')
axes[0, 0].plot(x, -f1_env, 'C3', lw=1.2, ls='--')
axes[0, 0].set_title(f'Well-behaved: $R={R1}$, $N={N1}$ ($R \\gg 1/N$)', fontsize=10)
axes[0, 0].set_ylabel('$f_{A,R,N}(x)$')
axes[0, 0].legend(fontsize=8)
# Its derivative
dx = x[1] - x[0]
f1_deriv = np.gradient(f1, dx)
axes[1, 0].plot(x, f1_deriv, 'C0', lw=0.8)
axes[1, 0].set_title(f'Derivative: oscillation term $\\sim N$ dominates', fontsize=10)
axes[1, 0].set_ylabel("$f'_{A,R,N}(x)$")
axes[1, 0].set_xlabel('$x$')
# Ill-behaved regime: R = 0.02, N = 20 (R < 1/N = 0.05)
R2, N2 = 0.02, 20
f2 = bump(x / R2) * np.sin(N2 * x)
f2_env = bump(x / R2)
axes[0, 1].plot(x, f2, 'C0', lw=1.2)
axes[0, 1].plot(x, f2_env, 'C3', lw=1.2, ls='--', label='envelope $\\phi(x/R)$')
axes[0, 1].plot(x, -f2_env, 'C3', lw=1.2, ls='--')
axes[0, 1].set_title(f'Ill-behaved: $R={R2}$, $N={N2}$ ($R < 1/N$)', fontsize=10)
axes[0, 1].set_xlim(-0.15, 0.15)
axes[0, 1].legend(fontsize=8)
# Its derivative
f2_deriv = np.gradient(f2, dx)
axes[1, 1].plot(x, f2_deriv, 'C0', lw=1.2)
axes[1, 1].set_title(f'Derivative: envelope term $\\sim 1/R$ dominates', fontsize=10)
axes[1, 1].set_xlabel('$x$')
axes[1, 1].set_xlim(-0.15, 0.15)
for ax in axes.flat:
ax.axhline(0, color='gray', lw=0.5, zorder=0)
ax.grid(True, alpha=0.3)
fig.suptitle('The uncertainty principle: well-behaved vs. ill-behaved regimes',
fontsize=12, fontweight='bold', y=1.01)
plt.tight_layout()
plt.show()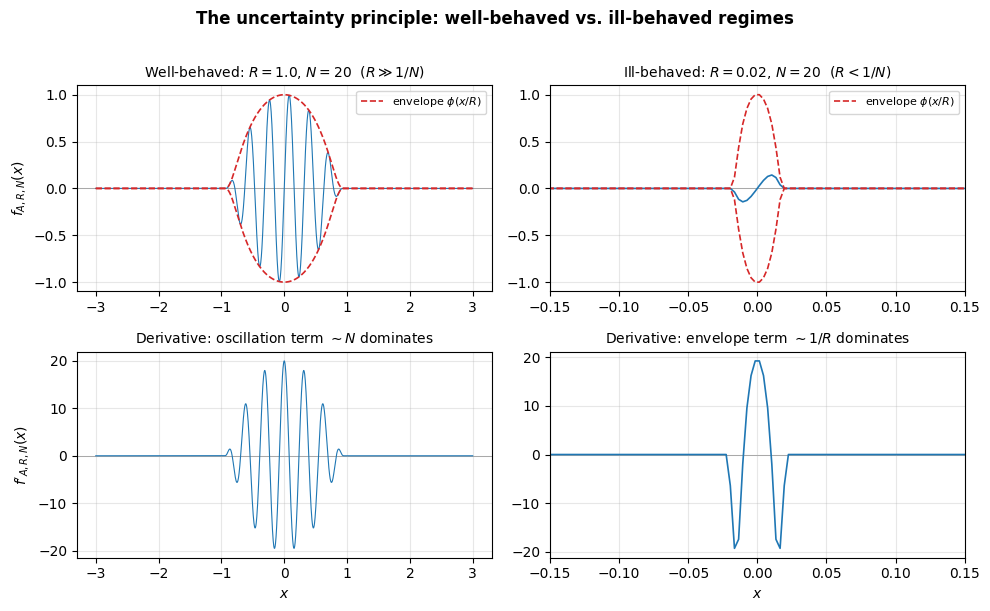
The dividing line between these regimes is the uncertainty principle for functions:
A function oscillating at frequency must spread over at least one wavelength in the oscillating direction: its spatial scale satisfies . This is the same constraint in any dimension, since it is a statement about a single oscillating direction, not about volume. The factor of that enters the Sobolev exponent comes from a different place: it is the volume scaling above, not from uncertainty itself.
Remark 2 (Classical uncertainty and Sobolev embedding)
The classical Fourier uncertainty principle states: if is concentrated in an interval of width , then its Fourier transform must be spread over a frequency range with . A function cannot be simultaneously localized in both space and frequency.
The Sobolev embedding theorem is the quantitative form of this principle. Trading derivatives of regularity (frequency control) for integrability (spatial behavior) is precisely the trade-off between frequency localization and spatial localization. The critical exponent quantifies the exchange rate, combining the uncertainty bound with volume scaling in dimensions.
Deriving the critical exponent from the uncertainty principle¶
Work in with the model function above. For , the highest-order term dominates in the well-behaved regime:
Normalize , so . The norm is then
We want to find the largest such that stays bounded across all well-behaved functions (all with ). The most dangerous case is the extremal one, where the function is as concentrated as uncertainty allows: . Substituting:
This is bounded for all iff , i.e. . The critical case gives exactly the Sobolev exponent:
Functions at the uncertainty boundary are the extremizers of the embedding: as concentrated as the uncertainty principle allows, making the norm as large as possible for a given norm. The Sobolev embedding theorem says that even these extremal functions have bounded norm.
Notice what each ingredient contributed:
Uncertainty () picked out the extremizer .
Volume scaling () is where the factor enters, yielding the exchange rate per derivative.
A purely dimensional derivation of the same Sobolev exponent, via rescaling , is worked through in ex-sobolev-scaling.
The general embedding theorem¶
Theorem 2 (Sobolev embedding theorem)
Let be open with suitable regularity (for instance Lipschitz boundary, or ).
Subcritical case (): , where is the Sobolev conjugate. Controlling derivatives in gives integrability up to .
Critical case (): for all (but not in general). The function is “almost continuous” but may have logarithmic singularities.
Supercritical case (): , where the orders of smoothness and Hölder regularity are determined by the Sobolev number
which records “how much regularity is left over after spending derivatives on dimension.” The split is
If : and . Equivalently and , so that .
If (boundary case): and the embedding holds for every , but in general not for (Lipschitz can fail).
Controlling enough derivatives in forces continuity, and even Hölder regularity, with the leftover budget split between integer smoothness () and a fractional Hölder exponent ().
Each clause is the intuition made precise. The subcritical exponent is the one forced by scaling and saturated by the uncertainty extremizers. The supercritical continuity statement is the 1D Poincaré phenomenon extended to general once enough derivatives are controlled to push past infinity. The critical case is the knife edge between them.
Proof 1 (Sketch)
This is a sketch, not a full proof. Every case is the 1D Poincaré calculation re-used in dimensions.
Recall the 1D identity , which fed either Cauchy-Schwarz (to get Hölder continuity) or integration in (to get control). In we apply the same identity along each coordinate axis: for each direction ,
The two regimes then split as follows.
Supercritical (, Morrey). Apply the 1D identity along a single line segment joining and , and estimate with Hölder. The result, , is verbatim the Poincaré Hölder estimate with the exponent adjusted for dimension.
Subcritical (, Gagliardo-Nirenberg-Sobolev). Multiply the axial bounds, take the power, and integrate. This is the same “integrate the pointwise bound” move from Poincaré, but done simultaneously in all directions, and it delivers . The case follows by applying this to ; iteration in raises the exponent by each step.
Critical (). The formula predicts , but narrowly fails (think ). Interpolating the subcritical estimates on either side recovers for every finite .
Compact embeddings: Rellich-Kondrachov¶
The Sobolev embedding theorem tells us that a bounded set in is bounded in . However, bounded in an infinite-dimensional space does not mean precompact (Remark 2). The remarkable fact is that if we ask for slightly less integrability ( instead of ), the embedding becomes compact: bounded sequences not only stay bounded but have convergent subsequences.
Theorem 3 (Rellich-Kondrachov compactness)
Let be bounded with Lipschitz boundary, and let , .
Subcritical (). With , the embedding is compact for every . The endpoint is continuous but not compact.
Critical (). The embedding is compact for every . (Continuous into BMO, but not into .)
Supercritical (). Writing (non-integer part), the embedding is compact for every (and in particular the embedding into is compact). The endpoint is continuous but not compact.
The pattern is uniform across regimes: compactness holds strictly below the sharp embedding exponent, and fails at it. The obstruction at the endpoint is always the same scaling/concentration phenomenon — the critical embedding is scale-invariant, so bumps keep a fixed norm while escaping every compact set. Giving up an arbitrarily small amount of the exponent breaks the scale invariance and restores compactness.
Proof 2
We prove the key case using Fourier analysis; the general case follows the same logic.
What we are actually proving. You might expect a compactness proof to take a bounded sequence and extract a Cauchy subsequence by hand. We do not do that. Instead, we use the characterization
(Definition 1), where totally bounded means: for every , the set is covered by finitely many -balls. So we never mention sequences. Instead we show that the -unit ball , viewed inside , is approximately finite-dimensional: at any resolution , every element of is within of a finite set.
This is a concrete instance of the general Kolmogorov-Riesz-Fréchet criterion (Theorem 2): a bounded set in is precompact iff it is equicontinuous under translation and tight. The gradient bound in the -norm is precisely what supplies the equicontinuity condition, since , and the bounded domain supplies tightness for free. Seen this way, Rellich-Kondrachov is not a miracle: it is Kolmogorov-Riesz with the hypothesis (2) automatically verified by gradient control. The Fourier-cutoff proof below is one convenient way to package the argument.
Once total boundedness is in hand, subsequence extraction is automatic: any bounded sequence lands in , and a totally bounded set in a complete space has convergent subsequences for free (this is the direction of the equivalence above). So the proof below is shorter and more structural than any direct subsequence argument would be, and it explains why compactness holds: because the derivative bound crushes the infinite tail of Fourier modes down to a size we can ignore, leaving only a finite-dimensional piece.
The plan in two lines:
Split at Fourier cutoff .
The tail is -small uniformly in , and the head lives in a finite-dimensional subspace.
That is the whole argument. The rest is bookkeeping.
Let and consider as a subset of . Working on a bounded domain (or torus) with Fourier basis , every has an expansion with
Split into low and high frequencies at a cutoff :
The high-frequency tail is uniformly small. For every :
This bound is uniform over all : it depends only on , not on the particular function. Given any , choose large enough that .
The low-frequency part is finite-dimensional. The projection maps into the span of the finitely many modes , which is a finite-dimensional subspace of . A bounded set in a finite-dimensional space is precompact (Bolzano-Weierstrass).
Combining: every element of is within (in ) of the precompact set . A set that can be approximated to arbitrary accuracy by precompact sets is itself precompact. So is precompact in , i.e. the embedding is compact.
How each hypothesis defeats each pathology¶
The proof makes explicit how the two hypotheses of Rellich-Kondrachov match the two pathologies (P1), (P2) identified at the start of the chapter:
The bound kills oscillation (P1). The decay forces the high-frequency tail to be uniformly small. Sequences like are ruled out because their derivatives blow up.
The bounded domain kills translation (P2). There is nowhere for the mass to escape to, and the Fourier basis is indexed by a discrete set, so “low frequency” means “finitely many modes.”
Both hypotheses are essential. On , is not compact, because translation sequences defeat it. On a bounded domain without the derivative bound, the identity is not compact in infinite dimensions, because oscillations defeat it.
Rellich-Kondrachov is the Sobolev-space counterpart of the Arzelà-Ascoli theorem (Theorem 1). In Arzelà-Ascoli, equicontinuity prevents rapid spatial oscillation; here, the bound prevents rapid frequency oscillation. In both cases, a regularity condition suppresses one pathology and a bounded domain suppresses the other. Together they force approximate finite-dimensionality.
Connection to compact operators¶
In the language of the compact operators chapter (Definition 1), the embedding is a compact operator: it maps the bounded unit ball to a precompact subset of . This is why compact embeddings and compact operators are interchangeable language.
The payoff for PDE is that compact embeddings upgrade weak convergence to strong convergence, which is essential for passing to the limit through nonlinearities. See the applications chapter for the full development: the weak formulation via Lax-Milgram (Theorem 1) and the nonlinear PDE example (nonlinear-pde-tools) both rely on Rellich-Kondrachov as a critical step.