This section, together with §Ridge Functions and Universal Approximation, covers material beyond the core MATH 551 syllabus. The two pages develop the rate-of-convergence question for neural networks; the content is included for interested students.
The previous page showed ridge functions are dense: any continuous on can be approximated by a wide-enough network. The natural question is how wide? For a fixed basis like tensor-product Chebyshev the answer is basis functions for targets in dimensions, exponential in : the curse of dimensionality. A one-hidden-layer ridge network reaches accuracy with no in the exponent (Barron 1993), provided has finite Barron norm . The proof is one-line Monte Carlo on an integral representation of .
What rate do neural networks give?¶
The previous page settled the density question: ridges are a basis, and Cybenko / Hornik tell us they can approximate any continuous target. What we do not yet have is a quantitative rate. For Chebyshev in 1D we know for analytic and for functions. Are there comparable statements for neural networks, and if so, in which dimensions ?
Before we can appreciate what neural networks buy us, we need to know what a fixed basis costs. The benchmark is tensor-product Chebyshev in ; we work it out in 2D first and then extract the general pattern.
2D Chebyshev series¶
A function has the 1D Chebyshev expansion . For a function , the natural extension is the tensor product: use in the first variable and in the second, and form all pairwise products,
Truncating to and gives an approximation built from basis functions . The coefficient is the inner product of against , computed by applying the 1D DCT along each axis: first along the axis on every -row, then along the axis on every column. The result is a 2D coefficient matrix whose entry is .
The same recipe extends to dimensions. A degree- tensor product in has basis functions and coefficients, computed by DCTs.
A 2D example¶
For a concrete look, fit a smooth non-separable function on by tensor-product Chebyshev with per axis, then plot the matrix of coefficients on a log scale.
import numpy as np
import matplotlib.pyplot as plt
from scipy.fft import dct
def chebpts(n):
return np.sin(np.pi * np.arange(-n+1, n, 2) / (2*(n-1)))
def polyfit2d(values):
"""2D type-2 Chebyshev coefs from values on the tensor grid.
Apply the 1D polyfit DCT along each axis in turn.
"""
n1, n2 = values.shape
c = dct(values[::-1, :], type=1, axis=0) / (n1 - 1)
c[0, :] *= 0.5; c[-1, :] *= 0.5
c = dct(c[:, ::-1], type=1, axis=1) / (n2 - 1)
c[:, 0] *= 0.5; c[:, -1] *= 0.5
return c
def chebval_T(xs, m):
"""T_0(x), ..., T_{m-1}(x) on the array xs."""
xs = np.asarray(xs); T = np.zeros((len(xs), m))
T[:, 0] = 1.0
if m > 1:
T[:, 1] = xs
for k in range(2, m):
T[:, k] = 2 * xs * T[:, k-1] - T[:, k-2]
return T
# Compute coefficients on Chebyshev nodes
n = 32
xc = chebpts(n)
Xc, Yc = np.meshgrid(xc, xc, indexing='ij')
f_target = lambda X, Y: np.exp(X * Y - 0.5 * X**2) # smooth, non-separable
c = polyfit2d(f_target(Xc, Yc))
# Evaluate the interpolant on a fine uniform grid
N_plot = 128
xs1d = np.linspace(-1, 1, N_plot)
Xg, Yg = np.meshgrid(xs1d, xs1d, indexing='ij')
target_grid = f_target(Xg, Yg)
Tx = chebval_T(xs1d, n)
recon = Tx @ c @ Tx.T
err_grid = recon - target_grid
rmse = float(np.sqrt(np.mean(err_grid**2)))
fig, axes = plt.subplots(1, 3, figsize=(15, 4.5))
# Panel 1: Chebyshev interpolant
im = axes[0].imshow(recon, extent=[-1, 1, -1, 1], origin='lower', cmap='viridis')
axes[0].set_title(rf'Chebyshev interpolant, $n={n}$ per axis')
axes[0].set_xlabel('$x$'); axes[0].set_ylabel('$y$')
plt.colorbar(im, ax=axes[0])
# Panel 2: error map
vmax = max(float(np.abs(err_grid).max()), 1e-15)
im = axes[1].imshow(err_grid, extent=[-1, 1, -1, 1], origin='lower',
cmap='RdBu_r', vmin=-vmax, vmax=vmax)
axes[1].set_title(rf'Error $f_n - f$, RMSE = {rmse:.1e}')
axes[1].set_xlabel('$x$')
plt.colorbar(im, ax=axes[1])
# Panel 3: coefficient heatmap
im = axes[2].imshow(np.log10(np.abs(c) + 1e-20), cmap='viridis',
origin='lower', vmin=-15, vmax=0)
plt.colorbar(im, ax=axes[2], label=r'$\log_{10}|c_{jk}|$')
axes[2].set_xlabel(r'$k$')
axes[2].set_ylabel(r'$j$')
axes[2].set_title(rf'$|c_{{jk}}|$, $n^2={n*n}$')
plt.tight_layout(); plt.show()
keep = np.abs(c) > 1e-12
print(f'Coefficients above 1e-12: {keep.sum()} of {n*n}')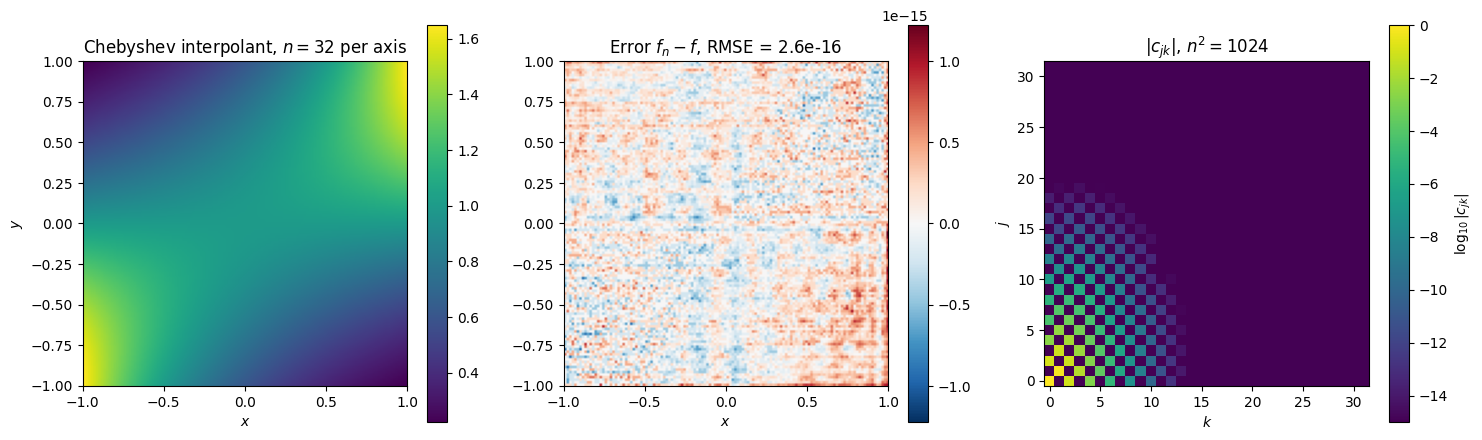
Coefficients above 1e-12: 87 of 1024
The left panel shows the Chebyshev interpolant at the full per axis: visually indistinguishable from the target. The middle panel shows the residual at machine-precision scale (RMSE ), so tensor-product Chebyshev exactly nails this analytic target with coefficients. The right panel shows where the coefficient mass lives: it concentrates in the low-frequency corner (small and ) and decays fast in both directions. Reaching 10-12 accuracy keeps about coefficients per axis, roughly in 2D. A 1D Chebyshev expansion of a comparably smooth function settles down in about 13 coefficients. The tensor product multiplies the per-axis cost: the total number of coefficients scales as with , giving coefficients in 3D, in 10D, and in 20D. The per-axis convergence is excellent; the -dimensional cost is unaffordable.
The curse of dimensionality¶
Definition 1 (Curse of dimensionality)
A numerical method for approximating a function to accuracy suffers from the curse of dimensionality if the number of basis functions, parameters, or function evaluations it needs grows exponentially in the dimension , i.e.
for some constant and per-axis smoothness . The cost remains finite for any fixed , but blows up so fast with that already moderate dimensions ( to 20) make the method unaffordable. The phrase is due to Bellman (1957) in the context of dynamic programming.
Tensor-product Chebyshev is a textbook example. The next subsection explains why this is not a quirk of polynomials but a structural property of any deterministic basis approximating Sobolev-class functions.
Where does really come from? A coefficient-decay count¶
The exponential cost is not specific to Chebyshev. It is built into how the Sobolev space , the space of functions on the cube whose first derivatives (in the weak sense) are square-integrable, sees the Chebyshev coefficients of . Here is the smoothness index: means one -derivative, two, and so on. (The same picture works for any reasonable Fourier basis on a bounded domain; a self-contained graduate-level treatment is on the MATH 725 Sobolev page.)
Sobolev norms measure frequency. The classical norms see size (height and width) of a function but are blind to oscillation: a function and a fast wiggle of it have the same norm. For with tensor-Chebyshev coefficients indexed by a multi-index , the Sobolev norm is equivalent to
with a frequency penalty : high-frequency coefficients (large ) cost more than low-frequency ones. is the assertion that the decay fast enough in for this sum to be finite. The integer is the smoothness index, and it is the same that appears in the rate below.
Approximating in to accuracy means approximating its Chebyshev coefficients. Truncating to multi-indices with , the tail satisfies
so to push the tail below we need . This is a Fourier uncertainty principle in disguise: accuracy in forces us to capture all Chebyshev coefficients with , no exceptions. The smaller , the larger ; the smoother (the larger ), the smaller the we need.
The curse comes from counting multi-indices in the box. The number of multi-indices with is , so the cost of resolving to accuracy is
The in the exponent is the volume of the multi-index box in , not a quirk of polynomials. Any deterministic basis has to cover that box.
For analytic (Bernstein ellipse with parameter ), the per-axis count drops to , and the -dimensional cost is instead of . Better, but still exponential in .
How neural networks handle this¶
The trick is to write itself as an integral against a parametric basis, then discretise the integral by Monte Carlo. The integral representation comes from the Fourier representation of .
From Fourier to ridges¶
For with (or for via Plancherel, which is the setting we mostly need), Fourier inversion writes as a continuous superposition of complex exponentials,
Each exponential depends on only through , like a ridge, but is unbounded (oscillates forever) and complex, so it does not live in the ridge basis . The bridge is to rewrite each oscillating exponential as a continuous superposition of bounded sigmoid ridges. We work this out for a single Fourier mode first, then assemble.
A worked example: on ¶
We work out how on , with fixed, becomes a continuous superposition of sigmoid ridges. The construction makes the -factor in the Barron norm explicit and shows that the ridges combine in pairs.
Step 1: a difference of two ridges is a bump. A single sigmoid ridge is a smooth step. The difference of two ridges with the same slope but opposite shifts ,
is a localised bump on the interval . Its width in is and its peak height is close to 2 for . As ranges over , sweeps through a family of bumps of increasing width: at the bump is degenerate, and at it covers the whole interval . The middle panel of the figure below shows one such .
Step 2: is an integral of these bumps. The layer-cake identity for on reads
where is the Heaviside step (a sharp ridge). The integrand at fixed is exactly a difference of two Heaviside steps with shifts , the sharp version of the bump from Step 1. Replacing the Heaviside by a sharp sigmoid, for large , puts the formula in pure-ridge form:
So is the integral over of ridge-difference bumps, weighted by . The formula is exact in the sharp limit .
Step 3: where the in the Barron norm comes from. The integration range in has length . To approximate the integral by a Riemann sum at spacing , we need ridge pairs. The number of ridge pairs needed to build scales linearly with the frequency . That linear scaling is the source of the factor in the Barron norm.
import numpy as np
import matplotlib.pyplot as plt
sigma = np.tanh
xs = np.linspace(-1, 1, 400)
omega = 6.0
t_demo = 2.0
fig, axes = plt.subplots(1, 3, figsize=(11, 3.4))
# Panel 1: two sigmoid ridges with slope omega, shifts +t and -t
ridge_plus = sigma(omega * xs + t_demo)
ridge_minus = sigma(omega * xs - t_demo)
axes[0].plot(xs, ridge_plus, 'C0-', lw=2, label=r'$\sigma(\omega x + t)$')
axes[0].plot(xs, ridge_minus, 'C1-', lw=2, label=r'$\sigma(\omega x - t)$')
axes[0].axhline(0, color='gray', lw=0.5)
axes[0].set_title(rf'Two ridges, $\omega={omega:.0f}$, $t={t_demo}$')
axes[0].set_xlabel(r'$x$'); axes[0].grid(alpha=0.3)
axes[0].legend(fontsize=8, loc='lower right')
# Panel 2: their difference = a localised bump Delta_t
bump_demo = ridge_plus - ridge_minus
axes[1].plot(xs, bump_demo, 'C2-', lw=2)
axes[1].fill_between(xs, 0, bump_demo, alpha=0.2, color='C2')
axes[1].axhline(0, color='gray', lw=0.5)
axes[1].set_title(r'Bump $\Delta_t = \sigma(\omega x+t) - \sigma(\omega x-t)$')
axes[1].set_xlabel(r'$x$'); axes[1].grid(alpha=0.3)
# Panel 3: layer-cake reconstruction of cos(omega x).
# cos(z) - cos(omega) = (1/2) int_0^omega sin(t) [sigma(alpha(z+t)) - sigma(alpha(z-t))] dt
# Use sharp sigmoids (alpha = 8) so the Heaviside-as-sigmoid limit is tight.
alpha = 8.0
n_t = 400
ts_pos = np.linspace(0.0, omega, n_t)
dt = ts_pos[1] - ts_pos[0]
target = np.cos(omega * xs)
recon = np.cos(omega) * np.ones_like(xs)
for t in ts_pos:
bump_t = sigma(alpha * (omega * xs + t)) - sigma(alpha * (omega * xs - t))
recon += 0.5 * np.sin(t) * bump_t * dt
axes[2].plot(xs, target, 'k-', lw=2, label=r'$\cos(\omega x)$')
axes[2].plot(xs, recon, 'C3--', lw=1.5, label='ridge integral')
axes[2].set_title(r'$\cos(\omega x)$ from differences of ridges')
axes[2].set_xlabel(r'$x$'); axes[2].grid(alpha=0.3)
axes[2].legend(fontsize=8)
plt.tight_layout()
plt.show()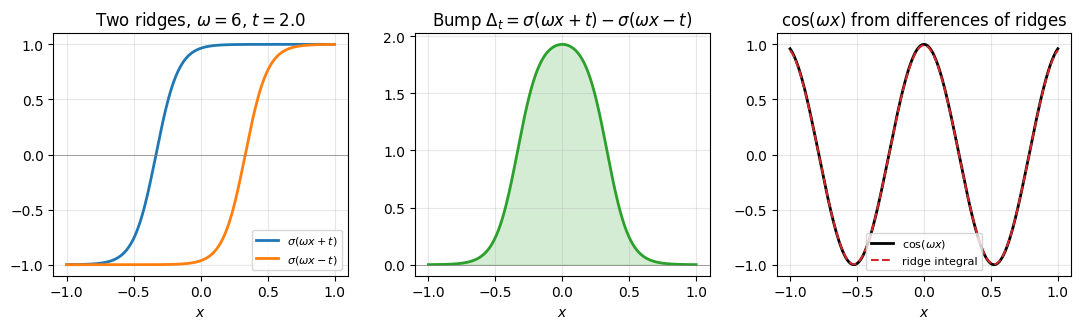
The right panel reconstructs via the layer-cake formula using 400 ridge pairs and sharp sigmoids (). The two curves match once the integral is discretised finely enough and the sigmoids are sharp enough; the formula is exact in the limit , . The mechanism, not the numerical accuracy, is the takeaway: a single Fourier mode of frequency is built from a continuous integral of differences of sigmoid ridges, with the count of ridge pairs scaling linearly in .
The general statement¶
Going from one Fourier mode to the full Fourier integral is an exercise in exchanging the order of integration. Carrying this out (Barron 1993, Theorem 2) gives
for some weight function , phase , and probability measure on . This is as a continuous neural network: an integral of bounded sigmoid ridges over the parameter , with playing the role of the constant of integration in a fundamental-theorem-of-calculus identity for ridges. The -factor from the worked example above appears under the integral and is what produces the in the Barron norm in §3.
From the continuous integral to a finite-width network¶
The integral representation is a “neural network with infinitely many neurons”, which we cannot evaluate. Approximate the continuous integral by Monte Carlo: sample iid and replace the integral by its sample average,
This is exactly a width- one-hidden-layer ridge network with weights drawn from . The continuous neural network becomes a finite-dimensional one through the same Monte Carlo discretisation we used for ordinary integration in the Monte Carlo notebook.
This is the probabilistic move: we replace classical (deterministic) integration, which places quadrature points on a grid, with Monte Carlo (random) sampling, which draws points from a probability distribution. A grid in carries the curse of dimensionality (its size scales as to reach spacing ); random samples cost regardless of . The trade is the convergence rate: deterministic methods can converge exponentially in (Chebyshev for analytic ), while MC converges only as . We accept the slower rate to escape the curse.
Why does this avoid the curse? The Monte Carlo error rate for any integrand is where is the variance of the integrand under , independent of the dimension of the integration domain. The remaining question is whether the variance of the Barron integrand can be bounded as grows. The next section identifies the condition under which it can: has finite Barron norm .
Barron space and the convergence theorem¶
The Barron norm¶
What controls the variance of the integrand ? Two ingredients: how much amplitude the integral representation needs, and how that amplitude couples to the spectrum of . Both turn out to be captured by a single quantity.
Definition 2 (Barron norm and Barron space)
Remark 1 (Examples in and out of Barron space)
A single smooth ridge has , no -dependence. Sums of ridges accumulate linearly in the number of summands. The Gaussian on has . Polynomials of low total degree on bounded are in .
Outside : anything with a heavy high-frequency tail. A half-space indicator has a jump and . Generic Lipschitz functions in dimensions usually have . A tensor product of smooth bumps is formally Barron but grows fast enough in that the rate is useless.
The Barron rate is conditional on having concentrated Fourier support. For ridge-type targets, smooth densities with light tails, and certain compositions, is dimension-free; for generic continuous functions in high , and the rate is meaningless.
Why this norm and not Sobolev¶
The Sobolev norm,
is an norm of with weight . It penalises high frequency, but it integrates over all of , treating frequency vectors in every direction equally. The Barron norm,
is an norm of . The exponent difference matters: counts only where is nonzero, while also penalises spread.
The contrast is sharpest on a single ridge in . The Fourier transform of a function that depends on only through is supported on the 1D line through the origin parallel to :
Two consequences:
The Barron integral collapses to a 1D integral along that line. Its value depends on and but not on .
The Sobolev integral tries to integrate a supported on a 1D line against a -dimensional measure. It is infinite for .
A function whose Fourier transform is concentrated on a low- dimensional set is invisible to Sobolev’s -over-the-ball machinery, but legible to Barron’s -on-the-support measure.
This is the structural explanation for how neural networks escape the curse on Barron-class targets. The Monte Carlo discretisation samples where the Fourier mass actually lives. For a ridge, the Fourier mass lives on a 1D line, so the samples concentrate there and ignore the rest of . A deterministic basis (Chebyshev) cannot do this; it pre-decides where to place basis functions before seeing , and ends up wasting most of them on directions where . Random sampling of the parameter adapts to the support of : the basis is built where the function lives, not over the whole ball.
Barron’s theorem¶
Theorem 1 (Barron 1993)
Let have and let have . For every and every probability measure on , there is a sigmoidal one-hidden-layer network of width with
The dimension enters through and , not through the exponent of . For ridge-type targets is dimension-free, so a width suffices for accuracy in any dimension. This is the entire content of the page: a rate, independent of , for functions with concentrated spectrum.
Proof 1
Use the integral representation with and . Then uniformly in , where . Drawing iid and averaging,
Some realisation achieves .
The proof is non-constructive: a good draw exists by averaging, but finding a specific good draw is a separate problem. In practice we solve it by gradient descent (which beats the typical MC draw by finding a better-than-typical configuration), but the existence guarantee comes from this one-line MC argument.
Examples in code¶
A 2D example, NN version¶
The 2D Chebyshev demo in §1 fit on with basis functions, keeping about 90 above 10-12. The Barron analogue is to fit the same target with random ridges and watch the error decay as the width grows.
import numpy as np
import matplotlib.pyplot as plt
sigma = np.tanh
def f_target(X, Y):
return np.exp(X * Y - 0.5 * X**2)
# Grid on [-1, 1]^2 (used for both fit and evaluation)
N = 48
xs1d = np.linspace(-1, 1, N)
Xg, Yg = np.meshgrid(xs1d, xs1d, indexing='ij')
target_grid = f_target(Xg, Yg)
Xs = np.stack([Xg.ravel(), Yg.ravel()], axis=1)
y_train = target_grid.ravel()
# Chebyshev basis matrix on the 1D grid: T_0(x), ..., T_{m-1}(x)
def chebval_T(xs, m):
xs = np.asarray(xs); T = np.zeros((len(xs), m))
T[:, 0] = 1.0
if m > 1:
T[:, 1] = xs
for k in range(2, m):
T[:, k] = 2 * xs * T[:, k-1] - T[:, k-2]
return T
# 2D tensor-product Chebyshev least-squares fit at increasing n_per_axis
n_per_axis = [2, 4, 8, 16]
cheb_totals = [na**2 for na in n_per_axis]
cheb_errors = []
Tx_full = chebval_T(xs1d, max(n_per_axis))
for na in n_per_axis:
Vc = np.einsum('aj,bk->abjk', Tx_full[:, :na], Tx_full[:, :na]).reshape(N*N, na*na)
coef, *_ = np.linalg.lstsq(Vc, y_train, rcond=None)
yhat_c = (Vc @ coef).reshape(N, N)
cheb_errors.append(float(np.sqrt(np.mean((yhat_c - target_grid)**2))))
# NN random-features fit at increasing width
ns = [16, 64, 128, 256, 1024]
fits = {}; nn_errors = []
for n in ns:
rng = np.random.default_rng(n)
ws = rng.normal(scale=2.0, size=(n, 2))
bs = rng.uniform(-2.0, 2.0, size=n)
V = sigma(Xs @ ws.T + bs)
a, *_ = np.linalg.lstsq(V, y_train, rcond=None)
yhat = (V @ a).reshape(N, N)
fits[n] = yhat
nn_errors.append(float(np.sqrt(np.mean((yhat - target_grid)**2))))
fig, axes = plt.subplots(1, 3, figsize=(13, 4.2),
gridspec_kw={'width_ratios': [1.3, 1.3, 1.0]})
# Panel 1: NN fit at moderate width
n_show = 128
im = axes[0].imshow(fits[n_show], extent=[-1, 1, -1, 1], origin='lower', cmap='viridis')
axes[0].set_title(rf'NN fit, $n={n_show}$, RMSE = {nn_errors[ns.index(n_show)]:.1e}')
axes[0].set_xlabel('$x$'); axes[0].set_ylabel('$y$')
plt.colorbar(im, ax=axes[0])
# Panel 2: error map at the same n
err_grid = fits[n_show] - target_grid
vmax = float(np.abs(err_grid).max())
im = axes[1].imshow(err_grid, extent=[-1, 1, -1, 1], origin='lower',
cmap='RdBu_r', vmin=-vmax, vmax=vmax)
axes[1].set_title(f'Error, $n={n_show}$')
axes[1].set_xlabel('$x$')
plt.colorbar(im, ax=axes[1])
# Panel 3: convergence — NN vs 2D Chebyshev, both as functions of total parameters n
axes[2].loglog(ns, nn_errors, 'o-', lw=2, label='NN (random features)')
axes[2].loglog(cheb_totals, cheb_errors, 's-', lw=2, label=r'2D Chebyshev ($n = n_a^2$)')
guide = nn_errors[0] * np.sqrt(ns[0]) / np.sqrt(np.array(ns))
axes[2].loglog(ns, guide, 'k--', alpha=0.4, label=r'$1/\sqrt{n}$ Barron guide')
axes[2].set_xlabel('total parameters $n$'); axes[2].set_ylabel('RMSE')
axes[2].set_title('Convergence vs $n$')
axes[2].grid(alpha=0.3, which='both'); axes[2].legend(fontsize=8)
plt.tight_layout(); plt.show()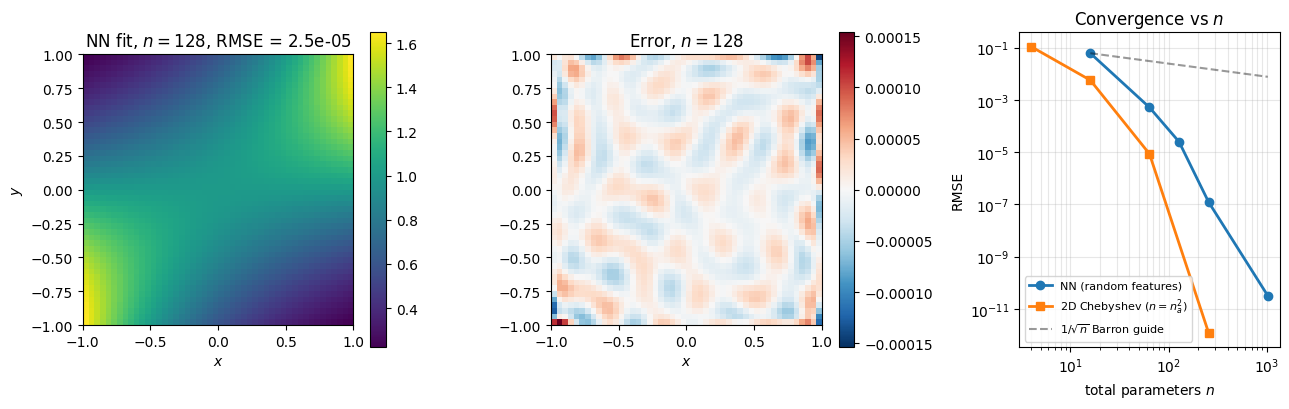
Random features at already capture the shape of the target (the contours line up); the error map shows residuals well below 10-2. Doubling the width roughly halves the RMSE, matching the Barron guide. The convergence panel overlays the 2D Chebyshev curve, with counted as the total number of coefficients ( where is per-axis): Chebyshev’s exponential rate in collapses the error to machine precision at modest totals, while NN’s slow rate continues linearly on the log-log plot. In 2D, on this analytic target, Chebyshev wins decisively; the curse of dimensionality has not yet bitten. The next two demos show what happens when grows.
Rate vs width in (Demo 2)¶
Fit a sum of ridges in at widths . Error drops sharply between and (the network catches the dominant ridge directions), then plateaus on a training-induced floor. The Barron bound is plotted as a guide; trained networks beat it because gradient descent finds parameters more efficient than typical Monte Carlo samples. Demo 2 of the companion notebook.
Dimension sweep (Demo 3)¶
Holding fixed, sweep on a sum-of-8-ridges target. Test RMSE stays in the 10-3 to 10-2 range across the entire sweep. A tensor-product polynomial would need coefficients for the same target, at and exceeding any computer’s memory by . The network handles it with hidden units throughout. Demo 3 of the companion notebook.
Caveats¶
Three things to keep in mind.
Optimisation. Finding good weights is non-convex. Gradient descent works empirically but no general guarantee that it reaches the network Barron’s theorem promises. Barron is approximation, not training.
Generalisation. From data , the empirical-risk minimiser has its own statistical error governed by Rademacher-style bounds. The in Barron is approximation (network width), not generalisation (sample size).
Beyond Barron. Many practical functions are not in . Active research extends to deep networks (deep Barron spaces, neural-ODE flow-induced spaces) and Banach-space variation norms. Each enlargement weakens the regularity assumption and the constants.
§Ridge Functions and Universal Approximation: the construction (eval, diff, int, fit) and the density theorem.
Monte Carlo notebook: the basic rate that powers Barron’s argument.
MATH 725 Sobolev page: Sobolev spaces in full, for the “what norms measure” framing used here.