A numerical algorithm cannot avoid the sensitivity inherent in the problem it solves. The best it can do is avoid making things worse. Backward stability is the formal statement of this goal: the computed answer is the exact solution of a slightly perturbed problem. Combined with the condition number, this gives the tightest error bound we can hope for.
Forward and Backward Error¶
When an algorithm computes an approximate solution to a problem , there are two ways to measure how good is.
Definition 1 (Forward and Backward Error)
For linear systems, the problem is . An algorithm produces . Then:
Forward error: , how far the computed solution is from the true one.
Backward error: the smallest such that . The computed solution exactly solves a nearby system.
Forward error is what we care about. Backward error is what we can control.
Theorem 1 (The Golden Rule)
where is the condition number of the problem.
This separates concerns cleanly:
The problem determines (how sensitive the answer is to perturbations).
The algorithm determines the backward error (how much perturbation it introduces).
Neither can compensate for the other. A stable algorithm applied to an ill-conditioned problem still gives a poor answer. A brilliant problem formulation is wasted on an unstable algorithm.
Sensitivity of Linear Systems¶
How sensitive is the solution to perturbations in and ?
A linear system has two inputs: the matrix and the vector . Both are subject to errors:
comes from measurements and always has some noise
comes from a model and its coefficients may be uncertain or stored with roundoff error
So we must understand how errors in both and propagate to errors in .
Theorem 2 (Sensitivity of Linear Systems)
For the linear system :
The quantity is the amplification factor from relative input perturbation to relative output error.
Proof 1
Numerically Singular Matrices¶
Recall that the condition number measures the ratio of maximum to minimum stretch of a unit vector. The sensitivity theorem tells us what this means in practice.
Rule of thumb: Expect to lose digits of accuracy.
| Condition Number | Digits Lost |
|---|---|
| ~ digits | |
| All digits |
See the Condition Numbers and Lost Digits notebook for concrete demonstrations with diagonal, Hilbert, and Vandermonde matrices.
But what does it mean geometrically for a matrix to be ill-conditioned? How close is it to being singular? The answer involves the geometry of the set of singular matrices in the operator norm.
The singular set is closed (optional)¶
Lemma 1 ( is closed)
The set of singular matrices is closed in the operator norm.
Proof 2
The determinant is a polynomial in the entries, so it is continuous. The singleton is closed in , so is closed as the preimage of a closed set under a continuous map.
Because is closed, every invertible matrix sits at some strictly positive distance from .
How far is an invertible matrix from ? The following theorem gives the exact answer.
Theorem 3 (Distance to Singularity)
For any invertible with the 2-norm, the distance to the set of singular matrices is
Proof 3
Demmel’s insight¶
Example 1 (Numerically singular matrices)
A matrix with is numerically indistinguishable from a singular matrix.
By Theorem 3, the relative distance from to the nearest singular matrix is
Now consider floating-point storage. The computer does not see . It sees where . The computer’s view of is a matrix somewhere inside a ball of radius centered at .
If :
The distance to the nearest singular matrix is .
The floating-point storage error is .
The uncertainty ball overlaps . The computer cannot tell whether is singular or not.
This is why ill-conditioned systems are fundamentally hard. It is not a failure of the algorithm. The problem itself is on the boundary of being unsolvable.
The figure below illustrates this geometry. Each matrix sits at distance from . The dashed circles show the floating-point uncertainty ball of radius . For , the ball overlaps .
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
from matplotlib.patches import FancyArrowPatch
fig, ax = plt.subplots(1, 1, figsize=(9, 5.5))
# --- Singular set as a smooth curve (codimension-1 surface in the schematic) ---
t = np.linspace(-1.0, 6.0, 500)
# A gently curving "wall" representing Σ = {det(A) = 0}
curve_x = 1.8 + 0.25 * np.sin(0.9 * t)
curve_y = t
ax.fill_betweenx(curve_y, -0.5, curve_x,
color='#d62728', alpha=0.08)
ax.plot(curve_x, curve_y, color='#d62728', lw=2.5, zorder=3)
ax.text(0.55, 5.2, r'$\Sigma = \{\det(A) = 0\}$',
fontsize=12, color='#d62728', ha='center', fontweight='bold')
# Floating-point ball radius (same for all, since ||A|| ~ same scale)
eps_r = 0.38
# --- A1: well-conditioned, far from Σ ---
A1 = np.array([6.0, 4.0])
# Distance to curve at this y-value
x_curve_at_A1 = 1.8 + 0.25 * np.sin(0.9 * A1[1])
dist1 = A1[0] - x_curve_at_A1
ax.plot(*A1, 'o', color='#1f77b4', ms=9, zorder=5)
ax.text(A1[0] + 0.15, A1[1] + 0.35, r'$A_1$',
fontsize=13, color='#1f77b4', fontweight='bold')
# Uncertainty ball
c1 = plt.Circle(A1, eps_r, fill=True, facecolor='#1f77b4', alpha=0.12,
edgecolor='#1f77b4', ls='--', lw=1.5, zorder=4)
ax.add_patch(c1)
# Distance bracket
ax.annotate('', xy=(x_curve_at_A1 + 0.05, A1[1]), xytext=(A1[0] - 0.05, A1[1]),
arrowprops=dict(arrowstyle='<->', color='#1f77b4', lw=1.5,
shrinkA=0, shrinkB=0))
ax.text((A1[0] + x_curve_at_A1) / 2, A1[1] - 0.35,
r'$\sigma_{\min}(A_1)$', fontsize=10, color='#1f77b4', ha='center')
# --- A2: ill-conditioned, close to Σ ---
A2 = np.array([2.85, 2.0])
x_curve_at_A2 = 1.8 + 0.25 * np.sin(0.9 * A2[1])
dist2 = A2[0] - x_curve_at_A2
ax.plot(*A2, 'o', color='#ff7f0e', ms=9, zorder=5)
ax.text(A2[0] + 0.05, A2[1] + 0.4, r'$A_2$',
fontsize=13, color='#ff7f0e', fontweight='bold')
# Uncertainty ball
c2 = plt.Circle(A2, eps_r, fill=True, facecolor='#ff7f0e', alpha=0.12,
edgecolor='#ff7f0e', ls='--', lw=1.5, zorder=4)
ax.add_patch(c2)
# Distance bracket
ax.annotate('', xy=(x_curve_at_A2 + 0.05, A2[1]), xytext=(A2[0] - 0.05, A2[1]),
arrowprops=dict(arrowstyle='<->', color='#ff7f0e', lw=1.5,
shrinkA=0, shrinkB=0))
ax.text((A2[0] + x_curve_at_A2) / 2, A2[1] - 0.35,
r'$\sigma_{\min}(A_2)$', fontsize=10, color='#ff7f0e', ha='center')
# --- A3: numerically singular, ball overlaps Σ ---
y3 = 0.5
x_curve_at_A3 = 1.8 + 0.25 * np.sin(0.9 * y3)
# sigma_min is small but visible; the eps-ball (radius 0.55) clearly overlaps Σ
dist3 = 0.35
eps_r3 = 0.55 # larger uncertainty ball for this matrix
A3 = np.array([x_curve_at_A3 + dist3, y3])
ax.plot(*A3, 'o', color='#2ca02c', ms=9, zorder=5)
ax.text(A3[0] + 0.55, A3[1] - 0.05, r'$A_3$',
fontsize=13, color='#2ca02c', fontweight='bold')
# Uncertainty ball -- this one overlaps Σ
c3 = plt.Circle(A3, eps_r3, fill=True, facecolor='#2ca02c', alpha=0.15,
edgecolor='#2ca02c', ls='--', lw=1.5, zorder=4)
ax.add_patch(c3)
# Distance arrow (horizontal, at the point's y-level)
ax.annotate('', xy=(x_curve_at_A3 + 0.03, A3[1]),
xytext=(A3[0] - 0.03, A3[1]),
arrowprops=dict(arrowstyle='<->', color='#2ca02c', lw=1.5,
shrinkA=0, shrinkB=0))
# Label above the arrow, shifted right to avoid overlapping the boundary
ax.text(A3[0] + 0.1, A3[1] + 0.25,
r'$\sigma_{\min}$', fontsize=10, color='#2ca02c', ha='left')
# --- Annotations ---
# Legend-style text box
legend_text = (
r'$A_1$: well-conditioned ($\kappa \approx 1$)' + '\n'
r'$A_2$: ill-conditioned ($\kappa \gg 1$)' + '\n'
r'$A_3$: numerically singular ($\kappa \gtrsim 1/\varepsilon_{\mathrm{mach}}$)'
)
ax.text(7.8, 1.3, legend_text, fontsize=9.5, va='center', ha='right',
bbox=dict(boxstyle='round,pad=0.5', facecolor='#f7f7f7',
edgecolor='#cccccc', alpha=0.95),
linespacing=1.8)
# Ball label
ax.text(7.8, -0.2,
r'Dashed circles = $\varepsilon_{\mathrm{mach}}\|A\|$'
'\n(floating-point uncertainty)',
fontsize=9, color='#666666', ha='right', va='top',
linespacing=1.6)
# Axis label
ax.text(4.5, -0.8, r'Space of matrices $\mathbb{R}^{n \times n}$ (schematic)',
fontsize=11, ha='center', color='#444444')
ax.set_xlim(-0.5, 8.2)
ax.set_ylim(-1.0, 5.8)
ax.set_aspect('equal')
ax.axis('off')
ax.set_title('Distance to singularity in the operator norm', fontsize=13, pad=12)
plt.tight_layout()
plt.show()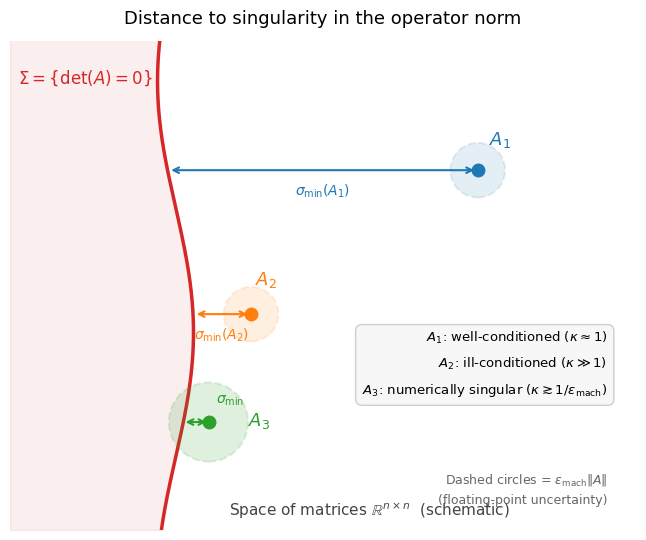
Residuals and Backward Error¶
Definition 2 (Residual)
Given a linear system and a computed solution , the residual is
The residual is cheap to compute and directly measures the backward error.
Proposition 1 (The Residual Measures Backward Error)
The relative backward error (perturbing only) equals . That is, is the exact solution of the perturbed system with .
Proof 4
Forward Stability¶
Now we turn to algorithms. We have two candidates for what “good algorithm” should mean. The first is the most natural wish.
Definition 3 (Forward Stable Algorithm)
An algorithm for solving is forward stable if the computed solution satisfies:
That is, the relative forward error is of order machine epsilon, regardless of the conditioning of .
This sounds ideal. Why not demand it?
Proposition 2 (Forward Stability Is Unattainable)
No algorithm for solving in floating-point arithmetic can be forward stable for all nonsingular .
Proof 5
The obstacle is not algorithmic; it is inherent in floating-point representation.
The input is already perturbed. When we store and in floating point, we do not have the true and . We have and with
Even before any computation begins, the problem has been perturbed. By the sensitivity theorem (Theorem 2), the exact solution of the perturbed problem already differs from by
No algorithm can undo this. The input perturbation gets amplified by . An algorithm that achieved forward error regardless of would have to “know” the true despite only having access to .
Forward stability requires , which is a condition on the problem, not the algorithm. For well-conditioned problems, forward and backward stability coincide. For ill-conditioned problems, forward stability is unachievable by any algorithm.
Backward Stability: The Right Standard¶
Since we cannot control forward error directly, we control what we can: the backward error. This leads to the Higham standard.
Definition 4 (Backward Stable Algorithm)
An algorithm for solving is backward stable if the computed solution satisfies:
That is, is the exact solution of a nearby problem.
Why this is the right standard. A backward stable algorithm introduces perturbations no larger than those already present from storing and in floating point. The algorithm does not make the situation any worse than it already is. You cannot ask for more than that.
Combined with the sensitivity theorem (Theorem 2):
This is the optimal forward error bound. It is optimal because:
The factor comes from the backward error, which is as small as possible.
The factor is intrinsic to the problem. No algorithm can remove it.
A backward stable algorithm achieves the best forward error that any algorithm can achieve on that problem. If the answer is not accurate enough, the problem is to blame, not the algorithm.
Example 2 (Why backward stability can still give a “bad” answer)
Consider the ill-conditioned system
The true solution is . Here .
Run a backward stable solver (say Householder QR) in double precision (). You might get, for example,
This answer is wrong in the 4th digit. But the algorithm is blameless. To see why, compute the residual:
So setting and gives
exactly, with . The computed is the true solution of a right-hand side that agrees with to 16 digits. (One could equally absorb the residual into via ; the backward error is not unique.)
Where did the 4 digits go? The condition number amplifies the input uncertainty:
The lost accuracy is real, but it was lost the moment was rounded into floating point. Any other backward stable algorithm produces an answer in the same neighborhood. The only way to do better is to reduce by reformulating the problem, or to use higher precision.
“Exact solution of a nearby problem” is exactly as strong as the data deserves. For well-conditioned , nearby problems have nearby solutions, so the answer is accurate. For ill-conditioned , nearby problems can have very different solutions, so accuracy is unavailable regardless of the algorithm.
Remark 1 (Which Algorithms Are Backward Stable?)
Householder QR is backward stable (see Theorem 2).
LU with partial pivoting is backward stable in practice, though the theoretical worst case allows growth factor (see the stability notebook).
Classical Gram-Schmidt is not backward stable: the loss of orthogonality scales with , not .
Practical Guideline: Always Check the Condition Number¶
Since the forward error satisfies
we should always estimate before trusting the solution. But how?
The Challenge¶
Computing exactly requires , which costs operations, as expensive as solving the system! We need a cheaper approach.
Hager’s Algorithm: A Clever Trick¶
The key insight (Hager, 1984; refined by Higham) is that we can estimate using only a few solves with the already-factored matrix.
Intuitive Derivation¶
We want where , without forming . Recall
So we want to find the unit-1-norm vector that makes largest. This is a constrained optimization; we will climb toward the maximum using only actions we can perform cheaply.
Step 1: evaluate the objective. For a given , form by solving . One triangular solve using the stored LU factors. The current value of the objective is .
Step 2: find an ascent direction. Write . Where differentiable,
To compute this gradient we need to apply to , that is, solve . A second triangular solve (same factors, transposed).
Step 3: move along the gradient. The feasible set is a polytope. A linear objective over a polytope is maximized at a vertex, and the vertices of the 1-norm ball are the signed unit vectors . The best vertex is the one that maximizes , namely
Jumping to this vertex is a single coordinate step, not a small increment.
Step 4: stop when no vertex improves. If , the current vertex already maximizes the linearized objective, so we have reached a local maximum of . Return as the estimate of .
The starting point is interior and avoids an unlucky first gradient. Each iteration costs two triangular solves; convergence typically takes 2-5 iterations. The estimate is a lower bound on , and in practice agrees with the true value to within a small factor.
A 2D picture¶
The geometry is easiest to see in 2D. The feasible set is the diamond with vertices . The objective is convex, so its maximum on the diamond is attained at one of these four vertices. Hager’s iteration is a vertex-hopping ascent: from the current point, the gradient singles out the vertex with as the best linear-prediction step.
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.patches import Polygon, FancyArrowPatch
B = np.array([[1.0, 2.0],
[3.0, 1.0]])
vertices = np.array([[1, 0], [0, 1], [-1, 0], [0, -1]], dtype=float)
vals = [np.linalg.norm(B @ v, 1) for v in vertices]
x0 = np.array([0.5, 0.5])
y0 = B @ x0
xi = np.sign(y0)
z = B.T @ xi
j = int(np.argmax(np.abs(z)))
x_new = np.sign(z[j]) * np.eye(2)[j]
fig, ax = plt.subplots(figsize=(7, 7))
ax.add_patch(Polygon(vertices, closed=True, facecolor='#1f77b4',
alpha=0.12, edgecolor='#1f77b4', lw=2))
for c in [1.0, 2.0, 3.0]:
ts = np.linspace(0, 2*np.pi, 400)
pts = []
for t in ts:
d = np.array([np.cos(t), np.sin(t)])
nb = np.linalg.norm(B @ d, 1)
if nb > 0:
pts.append((c / nb) * d)
pts = np.array(pts)
ax.plot(pts[:, 0], pts[:, 1], color='#888888', lw=0.8, alpha=0.7)
# label one level set
if c == 2.0:
ax.text(pts[50, 0]*1.02, pts[50, 1]*1.02, f'$f={c:.0f}$',
fontsize=9, color='#555555')
for v, val in zip(vertices, vals):
ax.plot(*v, 'o', color='#1f77b4', markersize=9, zorder=5)
off = 0.22 * v / max(np.linalg.norm(v), 1e-9)
ax.text(v[0] + off[0], v[1] + off[1], f'$f={val:.0f}$',
ha='center', va='center', fontsize=12, color='#1f77b4',
fontweight='bold')
ax.plot(*x0, 'ks', markersize=9, zorder=6)
ax.text(x0[0] - 0.05, x0[1] + 0.10, r'$\mathbf{x}_0=\frac{1}{2}\mathbf{1}$',
fontsize=12, ha='right')
g = z / np.linalg.norm(z)
ax.add_patch(FancyArrowPatch(x0, x0 + 0.4 * g,
arrowstyle='->', mutation_scale=18,
color='#2ca02c', lw=2.2))
ax.text(x0[0] + 0.4*g[0] + 0.05, x0[1] + 0.4*g[1],
r'$\nabla f$', fontsize=12, color='#2ca02c')
ax.add_patch(FancyArrowPatch(x0, x_new,
arrowstyle='->', mutation_scale=20,
color='#d62728', lw=2.4,
connectionstyle='arc3,rad=-0.18'))
ax.plot(*x_new, 'o', color='#d62728', markersize=11, zorder=6)
ax.text(x_new[0] + 0.05, x_new[1] - 0.22,
r'$\mathbf{x}_{\mathrm{new}}=\mathbf{e}_1$',
fontsize=12, color='#d62728')
ax.set_xlim(-1.6, 1.8)
ax.set_ylim(-1.6, 1.6)
ax.set_aspect('equal')
ax.axhline(0, color='lightgray', lw=0.5, zorder=0)
ax.axvline(0, color='lightgray', lw=0.5, zorder=0)
ax.set_xlabel('$x_1$')
ax.set_ylabel('$x_2$')
plt.tight_layout()
plt.show()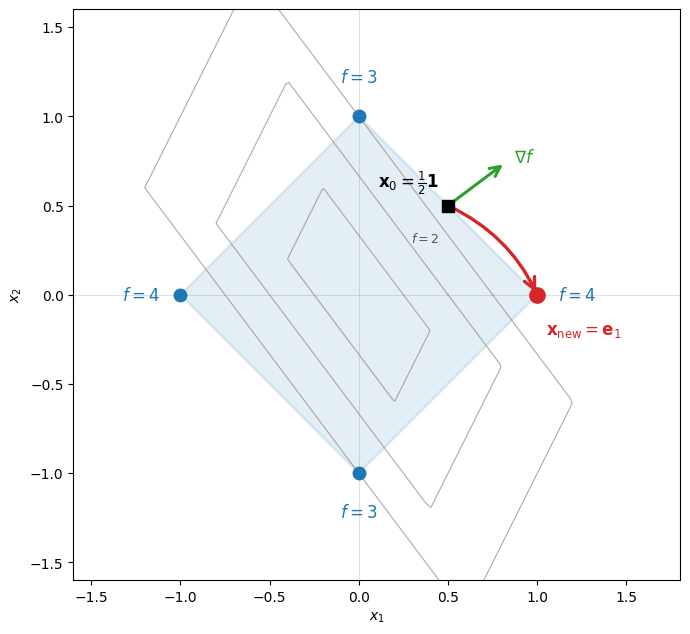
Reading the figure. The shaded diamond is the feasible set , with vertices (blue dots). Each vertex is labeled with the objective value ; the maximum, , is exactly (the largest column sum). Gray curves are level sets for . The black square is the interior start ; the green arrow is the gradient , which selects . The red arrow is the resulting vertex jump to , where the algorithm terminates.
Algorithm 1 (Hager’s 1-Norm Estimator)
Input: LU factorization of
Output: Estimate of
repeat
Solve (reuses the LU factorization!)
if then break
Solve
if then break
(unit vector with 1 in position )
return
Cost: Each iteration requires two triangular solves. Typically converges in 2-5 iterations, so total cost is , much cheaper than the factorization.
See the Condition Number Estimation notebook for a Python implementation.
Remark 2 (-norm version)
Applying Hager to estimates , since . So Hager gives cheap or estimates; the 2-norm would need an SVD.
Remark 3 (Why the 1-norm is sufficient)
Hager’s algorithm estimates , not . This is fine for two reasons.
First, all matrix norms on are equivalent. The sharp bounds between the 1-norm and 2-norm are:
so and can differ by at most a factor of . Since the forward error bound (Proposition 1) in the 1-norm is
we can convert to a 2-norm bound using for vectors and the matrix norm equivalence above. This gives
The extra factor of is pessimistic (it comes from worst-casing the norm conversion at every step). In practice the 1-norm bound is already a good estimate of the 2-norm error. For the “digits lost” rule of thumb, a factor of changes by at most , which is negligible.
Second, the 1-norm is cheap: costs and requires no singular value computation. The 2-norm is more expensive. Since Hager’s algorithm is a practical tool for cheap error bounds, the 1-norm is the natural choice.
The weighted residual ¶
LAPACK’s a-posteriori error estimates (e.g. xGERFS) do not use
but a slightly different and sharper quantity:
This is the weighted (or scaled) residual. It equals up to a constant whenever , but it is the optimal backward error when perturbing (Rigal–Gaches 1967): is the exact solution of for some with . A backward stable algorithm for a linear system is one where .
Theorem 4 (Golden Rule (weighted residual form))
For a computed solution of ,
Proof 6
From we get , hence . Divide by and multiply and divide by :
Compared to the form, is computable without reference to or separately (only , , and appear), and it combines cleanly with Hager’s estimator for . Paired in the -norm (see Remark 2), and are the standard package for practical forward error bounds.
Solving responsibly:
Factor: Compute (or ).
Solve: Use the factorization to obtain .
Estimate : Apply Hager’s algorithm to (see Remark 2). This costs only extra. For QR, the same idea works: estimate via triangular solves, then .
Compute the residual: .
Weighted residual: . If your solver lost backward stability; otherwise proceed.
Forward error bound: By Theorem 4,
If , the answer may be meaningless.
Steps 3-6 are essentially free compared to the factorization, and they give you a computable forward error bound.