This section reviews material from linear algebra (Math 235): vectors, matrices, and norms. It then introduces the condition number, which quantifies how sensitive a linear system is to perturbations. The emphasis is on the computational perspective: how do we measure size, and how does that connect to the accuracy of numerical algorithms?
Vectors are the objects we compute with; matrices are linear functions that act on vectors. To analyze algorithms, we need to measure size: norms for vectors, induced norms for matrices. The condition number measures the ratio of maximum to minimum stretch of unit vectors, and tells us how sensitive a linear system is to perturbations.
Vectors and Vector Spaces¶
The fundamental objects in numerical linear algebra are vectors, the elements of a vector space.
Definition 1 (Vector Space)
A vector space over is a set with two operations:
Addition: for
Scalar multiplication: for ,
satisfying the usual axioms (associativity, commutativity, distributivity, zero element, inverses).
The canonical example is , the space of column vectors with real components. But vector spaces are far more general:
Example 1 (Examples of Vector Spaces)
| Space | Elements | Dimension |
|---|---|---|
| Column vectors | ||
| Complex vectors | (over ) | |
| Polynomials of degree | ||
| Continuous functions on | ||
| Square-integrable functions |
The same linear algebra concepts (basis, dimension, linear maps, norms) apply to all these spaces. When you solve a PDE numerically, you’re doing linear algebra in a function space. The finite-dimensional theory () is the template for the infinite-dimensional theory (functional analysis).
This is why we emphasize the abstract structure: vectors are elements of a vector space, matrices are linear maps. The specifics of are just one instance.
Vector Norms¶
To analyze errors and convergence, we need to measure the “size” of vectors.
Definition 2 (Norm)
A norm on a vector space satisfies:
with equality iff (positive definiteness)
(homogeneity)
(triangle inequality)
A vector space equipped with a norm is called a normed vector space. If it’s also complete (Cauchy sequences converge), it’s a Banach space, the natural setting for analysis.
The -Norms on ¶
| Name | Formula | Interpretation |
|---|---|---|
| 1-norm | Manhattan distance | |
| 2-norm | Euclidean length | |
| -norm | Maximum component |
Norm Equivalence¶
Theorem 1 (Norm Equivalence)
All norms on are equivalent: for any two norms and , there exist constants such that:
This is a finite-dimensional phenomenon. In infinite dimensions (function spaces), different norms can give genuinely different notions of convergence, a key subtlety in PDE theory.
Function Space Norms¶
The same idea extends to functions:
| Space | Norm | Formula |
|---|---|---|
| Supremum norm | ||
| norm | ||
| norm |
These are the continuous analogs of the discrete -norms: sums become integrals.
Matrices as Linear Maps¶
Matrices are linear functions between vector spaces. A matrix defines:
Linearity means:
Every linear map corresponds to a unique matrix, and vice versa.
In infinite dimensions, linear maps between function spaces are called operators. Differential operators (), integral operators (), and solution operators for PDEs are all linear maps, the infinite-dimensional analogs of matrices.
The Matrix-Vector Product¶
Given and :
Cost: floating-point operations.
Two views:
| Row View | Column View |
|---|---|
| Each is a dot product: | is a linear combination: |
The column view reveals that lives in the column space (range) of .
Geometric Interpretation¶
| Matrix Type | Geometric Effect |
|---|---|
| Diagonal | Scaling along coordinate axes |
| Orthogonal () | Rotation and/or reflection |
| Symmetric | Scaling along eigenvector directions |
Matrix Norms¶
Since matrices are linear maps, we measure their size by how much they “stretch” vectors.
Definition 3 (Induced (Operator) Norm)
The maximum stretching factor over all unit vectors.
This definition works for any linear map between normed spaces. It is how we measure operators in functional analysis too.
| Name | Formula | Computation |
|---|---|---|
| 1-norm | Maximum column sum | |
| -norm | Maximum row sum | |
| 2-norm | Largest singular value |
Key properties:
(the defining inequality)
(submultiplicativity)
The 1-norm and -norm are cheap (just sums). The 2-norm requires singular values, which is more expensive but geometrically natural.
The Condition Number¶
The norm measures the maximum stretching factor over all unit vectors. What about the minimum?
Theorem 2 (Stretch Interpretation of and )
Definition 4 (Condition Number)
By Theorem 2, the condition number has a clean geometric meaning:
A matrix with stretches all directions roughly equally (like a rotation or uniform scaling). A matrix with stretches some directions far more than others, making the linear system sensitive to perturbations.
Geometric examples¶
Example 2 (Reading from a figure)
The image below shows the unit circle (left) and its image under a matrix (right).
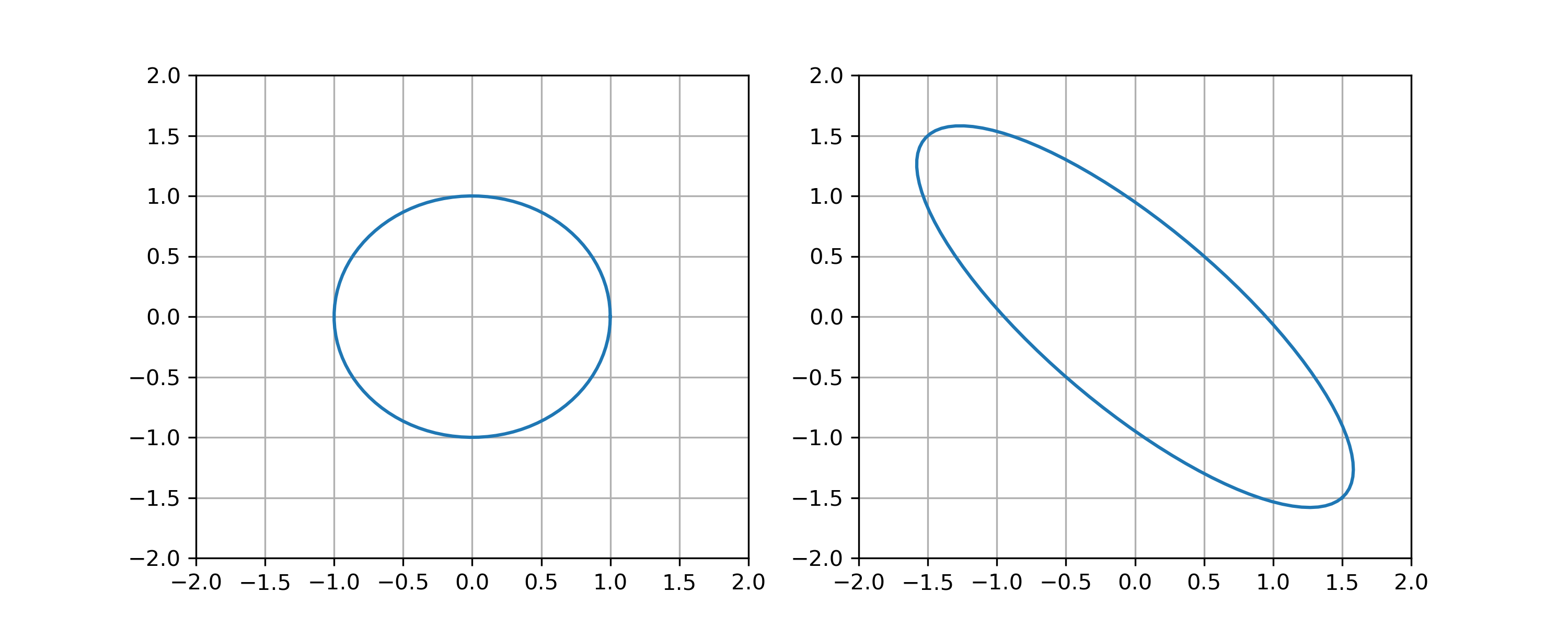
Figure 1:The unit circle (left) mapped to an ellipse under (right). The semi-axes of the ellipse are the singular values of : the maximum stretch is and the minimum stretch is .
The maximum stretch is . The minimum stretch is , so . The condition number is
This matrix is well-conditioned: the ellipse is only moderately elongated.
:::{prf:example} A more ill-conditioned matrix
:label: ex-condition-stretch2
Now a different $2 \times 2$ matrix:
:::{figure} /img/condition_stretch2.png
:label: fig-condition-stretch2
The unit circle (left) mapped to a more elongated ellipse under $A$ (right). The greater elongation reflects a larger ratio of maximum to minimum stretch, giving a higher condition number.The image is a much more elongated ellipse. From the figure, the maximum stretch is and the minimum stretch is , giving
## Linear Systems
We seek to solve $A\mathbf{x} = \mathbf{b}$ where
$A \in \mathbb{R}^{n \times n}$ and
$\mathbf{x}, \mathbf{b} \in \mathbb{R}^n$. The basic question is: when does a
unique solution exist?
:::{prf:theorem} Invertibility Conditions
:label: thm-invertibility-conditions
For a matrix $A \in \mathbb{R}^{n \times n}$, the following are equivalent:
1. $A$ is **invertible** (i.e., $A^{-1}$ exists)
2. $A\mathbf{x} = \mathbf{b}$ has a **unique solution** for each $\mathbf{b}$
3. $A\mathbf{x} = \mathbf{0}$ has only the **trivial solution** $\mathbf{x} = \mathbf{0}$
4. $\det(A) \neq 0$
5. All **eigenvalues** of $A$ are non-zeroExistence and uniqueness are settled by this theorem. The numerical questions are: how do we solve the system efficiently? and how sensitive is the solution to perturbations? The rest of this chapter develops the tools to answer both.