We have Barron’s bound in any dimension. The contrast: the deterministic alternative is a tensor-product Chebyshev grid that inherits the 1D rate at the price of basis functions. The exponential blow-up has nothing to do with the choice of polynomials and everything to do with how Sobolev regularity accounts for the spectrum.
Definition 1 (Curse of dimensionality)
A numerical method for approximating a function to accuracy suffers from the curse of dimensionality if the number of basis functions, parameters, or function evaluations it needs grows exponentially in the dimension , i.e.
for some constant and per-axis smoothness . The cost remains finite for any fixed , but blows up so fast with that already moderate dimensions ( to 20) make the method unaffordable. The phrase is due to Bellman (1957) in the context of dynamic programming.
Chebyshev series in 2D¶
Before the example we need to know what a 2D Chebyshev expansion is. A function has a 1D Chebyshev expansion . For a function , the natural extension is the tensor product: use in the first variable and in the second, and form all products,
Truncating to and gives an approximation built from basis functions . The coefficient is the inner product of against , computed in practice by applying the 1D DCT along each axis: first along the axis on every -row, then along the axis on every column. The result is a 2D coefficient matrix whose entry is .
The same recipe extends to dimensions. A degree- tensor product in has basis functions and coefficients, computed by DCTs.
A 2D example¶
For a concrete look, fit a smooth non-separable function on by tensor-product Chebyshev with per axis, then plot the matrix of coefficients on a log scale.
import numpy as np
import matplotlib.pyplot as plt
from scipy.fft import dct
def chebpts(n):
return np.sin(np.pi * np.arange(-n+1, n, 2) / (2*(n-1)))
def polyfit2d(values):
"""2D type-2 Chebyshev coefs from values on the tensor grid.
Apply the 1D polyfit DCT along each axis in turn.
"""
n1, n2 = values.shape
c = dct(values[::-1, :], type=1, axis=0) / (n1 - 1)
c[0, :] *= 0.5; c[-1, :] *= 0.5
c = dct(c[:, ::-1], type=1, axis=1) / (n2 - 1)
c[:, 0] *= 0.5; c[:, -1] *= 0.5
return c
n = 32
x = chebpts(n)
X, Y = np.meshgrid(x, x, indexing='ij')
f = np.exp(X * Y - 0.5 * X**2) # smooth, non-separable
c = polyfit2d(f)
fig, ax = plt.subplots(figsize=(6, 5))
im = ax.imshow(np.log10(np.abs(c) + 1e-20), cmap='viridis',
origin='lower', vmin=-15, vmax=0)
plt.colorbar(im, ax=ax, label=r'$\log_{10}|c_{jk}|$')
ax.set_xlabel(r'$k$ ($y$-direction index)')
ax.set_ylabel(r'$j$ ($x$-direction index)')
ax.set_title(rf'2D Chebyshev coefficients of $e^{{xy - x^2/2}}$, $n^2={n*n}$')
plt.tight_layout(); plt.show()
keep = np.abs(c) > 1e-12
print(f'Coefficients above 1e-12: {keep.sum()} of {n*n}')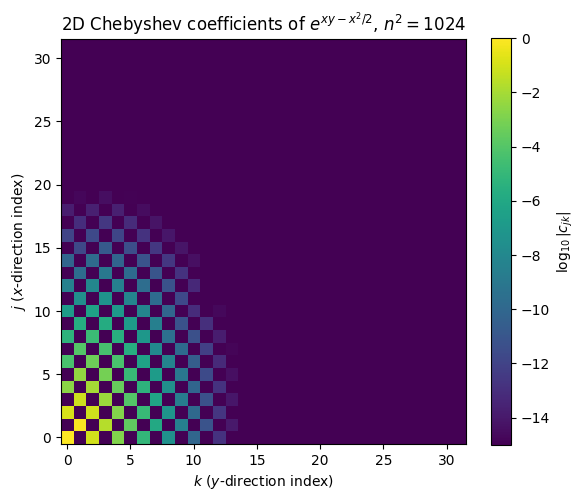
Coefficients above 1e-12: 87 of 1024
The mass concentrates in the low-frequency corner (small and ), and the entries decay fast in both directions. Even so, reaching 10-12 accuracy keeps about 9 coefficients per axis, roughly 90 total. A 1D Chebyshev expansion of a comparably smooth function settles down in about 13 coefficients. The tensor product roughly multiplies the per-axis cost: in 3D the same target would keep coefficients, in 10D about , even though the per-axis convergence is excellent.
Where the -dependence comes from¶
The exponential cost is not specific to Chebyshev. It is built into how Sobolev regularity accounts for the spectrum.
A function has finite. Truncating the spectrum at frequency , the L² tail is bounded by
so to reach accuracy we need . To resolve every mode below on a grid we need one basis function per resolvable mode in the ball , whose volume is . Hence
The in the exponent is the volume of the frequency ball, not a quirk of the polynomial basis. Any deterministic discretisation has to cover that volume.
For an analytic function (Bernstein ellipse with parameter ), per axis, so the cost is instead of . Better, but still exponential in .
What Barron’s bound buys¶
For a Barron-class target the trade becomes
with no in the exponent. The price is the slow rate; the prize is escaping the curse.