A one-hidden-layer neural network is a basis expansion in ridge functions . Cybenko (1989) and Hornik (1991) showed this basis is dense in , just like polynomials. Density is not the headline; the rate is. Barron’s theorem says that for with bounded Barron norm , a width- network reaches accuracy , with no in the rate.
A neural network as a basis expansion¶
A one-hidden-layer network is
with , weights , biases , output coefficients , and a fixed non-linearity . Stacking the as rows of a matrix gives the matrix form
with acting elementwise.
Each term is a ridge function: a 1D function depending on only through , extruded along the directions perpendicular to . A network is a sum of such ridges; controls the direction, shifts it, scales it.
Compare with a Chebyshev expansion . Both are linear combinations of basis functions. The Chebyshev basis is fixed; the ridge basis is parameterised by that we can choose.
A 1D ridge network: evaluation, differentiation, integration¶
In one variable a ridge is just a shifted, scaled copy of : with . The basis is parameterised but each basis function is something we can draw on a single axis. Before doing any algebra, look at it.
What a ridge basis looks like¶
Three panels. The left shows three single ridges with different . The slope at the inflection point is for , so controls how fast the ridge transitions from one saturation level to the other; the sign of flips left and right; shifts the inflection point to . The middle panel overlays a few , dashed unscaled and solid scaled, to show how rescales each individual ridge. The right panel adds them up and overlays a target.
import numpy as np
import matplotlib.pyplot as plt
sigma = np.tanh
xs = np.linspace(-2, 2, 400)
fig, axes = plt.subplots(1, 3, figsize=(11, 3.2))
# Panel 1: three single ridges
ax = axes[0]
for w, b, label in [(1, 0, r"$w=1,\ b=0$"),
(4, 0, r"$w=4,\ b=0$"),
(-2, 1, r"$w=-2,\ b=1$")]:
ax.plot(xs, sigma(w * xs + b), label=label)
ax.set_title(r"Single ridges $\sigma(wx+b)$")
ax.legend(fontsize=8, loc="lower right")
ax.set_xlabel(r"$x$"); ax.grid(alpha=0.3)
# Panel 2: scaled vs unscaled
ax = axes[1]
params = [(3, -1, 1.0), (-2, 0.5, -0.7), (1.5, 1, 1.3)]
for w, b, a in params:
ax.plot(xs, sigma(w * xs + b), '--', alpha=0.45)
ax.plot(xs, a * sigma(w * xs + b), '-')
ax.set_title(r"Scaled ridges $a_k\,\sigma(w_k x+b_k)$")
ax.set_xlabel(r"$x$"); ax.grid(alpha=0.3)
# Panel 3: sum vs target
ax = axes[2]
target = lambda t: np.sin(2 * np.pi * t) * np.exp(-0.5 * t**2)
rng = np.random.default_rng(0)
n = 30
ws = rng.normal(scale=4, size=n)
bs = rng.uniform(-3, 3, size=n)
V = sigma(np.outer(xs, ws) + bs)
y = target(xs)
a, *_ = np.linalg.lstsq(V, y, rcond=None)
ax.plot(xs, y, 'k-', lw=2, label="target")
ax.plot(xs, V @ a, '--', lw=1.5, label=f"sum, $n={n}$")
ax.set_title(r"Sum $\sum_k a_k\,\sigma(w_k x+b_k)$")
ax.legend(fontsize=8); ax.set_xlabel(r"$x$"); ax.grid(alpha=0.3)
plt.tight_layout()
plt.show()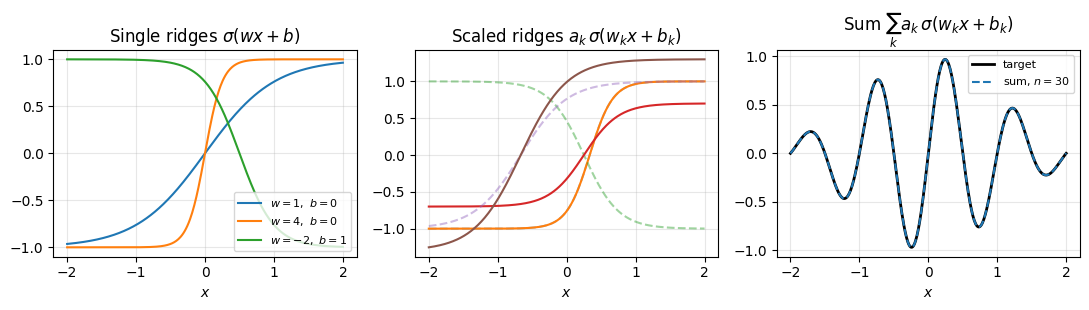
The takeaway: each ridge contributes one bend, localised to a region of width around . Outside that region the ridge is essentially constant and adds nothing. Contrast with Chebyshev, where every oscillates across the entire interval . Ridges are local, polynomials are global. This single fact drives the difference in behaviour in high dimensions: a -variable ridge is a 1D bump pulled along flat directions, so its cost does not multiply with , while a tensor-product basis of global polynomials does.
Random features: the linear case¶
Treat as fixed up front and let only vary, the random-features view. The ridge basis is then a fixed basis like , and every operation is linear in the coefficient vector . We come back to the trained case at the end.
Evaluation¶
at a point. For a batch , this is with . Cost , the same shape as Chebyshev’s value-from-coefficient map.
Differentiation¶
, so
The coefficient map is with , expressed in the related basis . Like Chebyshev: differentiation maps to a different family, and a recurrence converts back. For ridges we evaluate in the -basis directly.
Integration¶
If then . For , . The definite integral is
A linear functional with precomputed moments, identical in shape to the Chebyshev integration construction.
Fitting¶
The coefficients minimise , linear least squares. With Chebyshev nodes for and the -basis the matrix is structured and a DCT solves it in . With random ridges no such structure, but the linear solve via pseudoinverse is still cheap, and there is no non-convex search.
This is the random-features network. Drawing from a fixed distribution and solving the linear least-squares problem for is exactly what Barron’s existence proof produces below: random samples from an integral representation of .
The trained case¶
If we let vary too, the loss
is non-convex. The standard tool is gradient descent (Adam in practice), used in Demo 1 of the companion notebook. The trade is linearity for adaptivity: random features keeps the basis fixed and the solve linear, a trained network places ridge directions where the structure of lives. In 1D the polynomial story already wins; the trade flips in high .
From construction to guarantees¶
The 1D story above shows ridges are a basis we can compute with: we can evaluate, differentiate, integrate, and fit, exactly as we did with . Two questions remain:
Can ridges represent every continuous function? Density is the property that lets us call this a basis at all, and is what universal approximation answers.
How efficiently? Density allows arbitrary error in the limit; it says nothing about how the required width scales with the target function or the input dimension. Barron’s theorem answers this.
These two questions have separate answers and the second is where the dimension-dependence (or lack of it) actually lives.
The universal approximation theorem¶
Stone-Weierstrass already gives polynomial density in for compact , so “any continuous function in any dimension is approximable by polynomials” was a solved problem. Cybenko (1989) and Hornik (1991) added that ridge functions are also dense.
Theorem 1 (Universal Approximation (Cybenko 1989, Hornik 1991))
Let be continuous and non-polynomial. Let be continuous on a bounded , and . There is a width and parameters with
where .
The non-polynomial requirement is structural: a sum of polynomial ridges is itself a polynomial of bounded degree, which is not dense.
Two activations dominate in practice, both non-polynomial:
ReLU, : piecewise linear, unbounded, cheap; the modern default.
tanh / sigmoid: bounded and smooth, what the original proofs used; gradients vanish in the saturation regions.
Density alone is not new news. The reason to care about ridges is the rate, which depends on the function class.
What “function on ” actually covers¶
The phrase is more general than it sounds. The input is a list of numbers, and almost any object we can encode reduces to that:
pixel intensities of an image, to 106;
a learned embedding of a sentence, to 104;
atomic positions, charges, and types in a molecule;
the state of a game or control system at one moment;
the parameters of a physical or financial model whose outcome we want to predict.
Universal approximation says a wide-enough one-hidden-layer network can approximate “image class label”, “sentence translation”, “molecule binding energy”, and so on. That is a strong representability statement, but it is silent on how large “wide-enough” is, and the worst-case answer is exponential in . Real-world high-dimensional learning works because the targets people care about live in classes where the required width is manageable. Barron’s theorem identifies one such class.
A first experiment: fitting ¶
Train a width-20 network with on over
. After 2000 Adam steps the network reaches
pointwise error. The adaptive Chebyshev chebfit_adaptive from
A Chebyshev Toolbox: Doing Linear Algebra with Functions reaches machine precision on
the same function with about 20 coefficients, in one DCT. Both get
arbitrarily close to ; the network needs thousands of
gradient steps and still plateaus at 10-2. In 1D the network is
strictly worse than what we already have. The picture flips in high
. Demo 1 of the companion
notebook.
Integral representation¶
The bridge between and a one-hidden-layer network is a Fourier-side identity. For nice enough with Fourier transform ,
Splitting into real ridge components and recasting as differences of sigmoidal ridges (Barron 1993, Theorem 2),
for some weight , phase , and probability measure .
Where does the factor in the Barron norm come from? A sinusoid is itself not a ridge (the activation is bounded and monotone, oscillates). But it is a difference of sigmoidal ridges: imagine forming one period of by adding rescaled saturating sigmoids that turn on and off in the right places. To build a wave of frequency from sigmoids that saturate at , the amplitudes have to scale with so the steep up-and-down of the wave can be matched by sigmoid steps that rise and fall on a length scale . That is the only place enters, and it is exactly the weight that appears under the Barron integral. High-frequency content costs more ridge amplitude, in proportion to the frequency, so the Barron norm weights it accordingly.
Sampling and averaging gives a width- ridge network as a Monte Carlo estimator. By Monte Carlo Methods, the error of an MC estimator of an integral with variance is , regardless of dimension. The variance is bounded by the Barron norm.
The Barron norm¶
Definition 1 (Barron norm and Barron space)
Why an L¹ moment of the spectrum and not an L² Sobolev norm? Take a single ridge in . Its Fourier transform is concentrated on the 1D line through the origin parallel to . The Barron integral collapses to something that depends only on and : no appears, even though the function lives in . The Sobolev norm tries to integrate over all of with a high-frequency penalty, and is in fact infinite for a strict ridge when .
The Barron norm registers concentration of the spectrum; the Sobolev norm assumes spread. Real-world high-dimensional functions tend to have concentrated spectra (decision boundaries given by ridges, densities with light tails), and Barron is the right norm for them.
Barron’s theorem¶
Theorem 2 (Barron 1993)
Let have and let have . For every and every probability measure on , there is a sigmoidal one-hidden-layer network of width with
The dimension enters through and , not through the exponent of . For ridge functions is dimension-free, so the network needs neurons regardless of . This is the entire content of the page: a rate, in any dimension, for functions whose spectrum is concentrated.
Proof 1
Use the integral representation with and . Then uniformly in , where . Drawing and averaging,
Some realisation achieves .
The proof is non-constructive: weights exist by averaging, but finding a specific good draw is a separate problem, which in practice we solve by gradient descent.
The rate, in code¶
A single ridge is too easy (a width-1 network solves it). For a non-trivial test, fit a sum of ridges in at widths . Error drops sharply between 8 and 32 (the network catches the dominant ridge directions), then plateaus on a training-induced floor. The Barron bound is plotted as a guide; trained networks beat it because gradient descent finds parameters more efficient than typical Monte Carlo samples. Demo 2 of the companion notebook.
What sits in and out of Barron space¶
A single smooth ridge has , no -dependence. Sums accumulate linearly in the number of summands. The Gaussian on has . Polynomials of low total degree are in .
Outside : anything with a heavy high-frequency tail. A half-space indicator has a jump and . Generic Lipschitz functions in dimensions usually have infinite. A tensor product of smooth bumps is formally Barron but the constant grows fast enough in that the rate is useless.
The Barron rate is conditional on a concentrated spectrum. For ridge-type targets, smooth densities, and certain compositions it holds with dimension-free constants; for generic continuous functions in high it does not.
Dimension dependence, in code¶
Holding the network width fixed at , sweep on a sum-of-8-ridges target. The test RMSE stays in the 10-3 to 10-2 range across the whole sweep. A tensor-product polynomial would need coefficients for the same target, at and exceeding any computer’s memory by . The network handles it with 64 hidden units throughout. Demo 3 of the companion notebook.
Summary¶
Three caveats.
Optimisation. Finding good weights is non-convex. Gradient descent works empirically but no general guarantee that it reaches the network Barron’s theorem promises. Barron is approximation, not training.
Generalisation. From data , the empirical-risk minimiser has its own statistical error governed by Rademacher-style bounds. The in Barron is approximation (network width), not generalisation (sample size).
Beyond Barron. Many practical functions are not in . Active research extends to deep networks (deep Barron spaces, neural-ODE flow-induced spaces) and Banach-space variation norms. Each enlargement weakens the regularity assumption and the constants.