Root finding problems can be reformulated as fixed point problems. The key insight: if near a fixed point, the iteration converges. This provides a unified framework for analyzing iterative methods.
Fixed Points¶
Definition 1 (Fixed Point)
is a fixed point of if .
The basic idea: reformulate a root-finding problem as a fixed-point problem.
There are many ways to do this! Given , you could write:
for any nonzero
(this gives Newton’s method!)
The choice of matters enormously for convergence, as we’ll see.
The Algorithm¶
The fixed-point iteration is beautifully simple.
Algorithm 1 (Fixed Point Iteration)
Input: Function , initial guess , tolerance , max iterations
Output: Approximate fixed point
for :
if : return
return (or indicate failure)
That’s it. But this simplicity raises three fundamental questions:
Does a fixed point even exist? And if so, is it unique?
Does the iteration converge? Starting from , will the sequence actually reach the fixed point?
How fast does it converge? Can we do better than bisection’s linear rate?
The answer to all three turns on a single quantity: near the fixed point. When , the map is a contraction: it pulls nearby points closer together, and the iteration spirals inward. When , it pushes points apart, and the iteration diverges. The choice of controls , which is why different reformulations of the same problem can behave so differently.
Why the Choice of Matters¶
Consider finding the root of (i.e., finding ).
Here are three valid reformulations:
G1: From , we get
G2: Add to both sides:
G3: Divide by :
All three have as a fixed point. But their behavior is dramatically different:
G1 cycles forever, never converging
G2 converges slowly (linearly)
G3 converges rapidly (quadratically, this is Newton’s method!)
Fixed Point Iteration Demo: Compare G1, G2, G3 convergence behavior
Existence, Uniqueness and Convergence¶
There are three separate questions to answer, each requiring its own condition:
1. Existence: Does a fixed point exist at all? This only requires that maps into itself: . Geometrically, this traps the graph of inside the box . Since and , the graph must cross the diagonal . That crossing is a fixed point (left panel). But there could be many crossings.
2. Uniqueness: Is there only one fixed point? This requires on the interval. The map is then a contraction: it shrinks distances. If two fixed points existed, the MVT gives , a contradiction since . Geometrically, means the graph is everywhere less steep than the diagonal, so it can only cross once (center panel). When , the graph can be steeper than the diagonal, allowing multiple crossings (right panel).
3. Convergence: Does the iteration actually reach the fixed point? This is a question about the dynamics of iterating , not just its graph. The same contraction condition guarantees convergence: each step shrinks the distance to the fixed point, so the cobweb spirals inward (center panel). When , the iteration amplifies errors. The cobweb diverges away from the fixed point even if you start nearby (right panel).
import numpy as np
import matplotlib.pyplot as plt
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
ax1, ax2, ax3 = axes
a, b = 0.5, 2.5
x = np.linspace(a, b, 200)
from scipy.optimize import brentq
def plot_box(ax):
ax.plot([a, b, b, a, a], [a, a, b, b, a], 'k-', linewidth=1.5)
ax.fill_between([a, b], a, b, alpha=0.08, color='blue')
ax.plot(x, x, 'k--', linewidth=1, alpha=0.6)
def find_and_mark_crossings(ax, g):
"""Find and mark fixed points; return list of roots."""
y = g(x)
h = y - x
roots = []
for i in range(len(h)-1):
if h[i] * h[i+1] < 0:
root = brentq(lambda t: g(t) - t, x[i], x[i+1])
roots.append(root)
ax.plot(root, root, 'ro', markersize=8, zorder=5)
return roots
def setup_ax(ax, title):
ax.set_xlim(a - 0.15, b + 0.15)
ax.set_ylim(a - 0.15, b + 0.15)
ax.set_xlabel('$x$')
ax.set_ylabel('$y$')
ax.set_title(title)
ax.set_aspect('equal')
# --- Panel 1: Existence (g maps [a,b] into [a,b]) ---
g1 = lambda x: 0.4*np.sin(3*x) + 1.5
plot_box(ax1)
ax1.plot(x, g1(x), 'b-', linewidth=2.5)
find_and_mark_crossings(ax1, g1)
setup_ax(ax1, 'Existence: $g([a,b]) \\subseteq [a,b]$\ngraph must cross $y = x$')
# --- Panel 2: Contraction (|g'| < 1) => unique + converges ---
g2 = lambda x: 0.4*x + 0.9 # |g'| = 0.4 < 1
plot_box(ax2)
ax2.plot(x, g2(x), 'b-', linewidth=2.5)
find_and_mark_crossings(ax2, g2)
# Cobweb showing contraction
x_cob = 2.2
ax2.plot(x_cob, x_cob, 'k*', markersize=12, zorder=6)
for _ in range(6):
x_next = g2(x_cob)
ax2.plot([x_cob, x_cob], [x_cob, x_next], 'g-', alpha=0.5, linewidth=1)
ax2.plot([x_cob, x_next], [x_next, x_next], 'g-', alpha=0.5, linewidth=1)
x_cob = x_next
ax2.plot(x_cob, x_cob, 'rs', markersize=8, zorder=6)
setup_ax(ax2, "Contraction: $|g'| < 1$\ncobweb spirals in, unique fixed point")
# --- Panel 3: Nonlinear with |g'| > 1 in middle => multiple fixed points ---
# Steep S-curve: maps [a,b] into [a,b] but |g'| > 1 in the middle
g3 = lambda x: 1.5 + 0.95*np.tanh(2.5*(x - 1.5))
plot_box(ax3)
ax3.plot(x, g3(x), 'r-', linewidth=2.5)
roots = find_and_mark_crossings(ax3, g3)
# Cobweb starting near the central fixed point, showing divergence away from it
# The middle root is the unstable one
middle_root = sorted(roots)[1]
x_cob = middle_root + 0.05
ax3.plot(x_cob, x_cob, 'k*', markersize=12, zorder=6)
for _ in range(12):
x_next = g3(x_cob)
if x_next < a - 0.3 or x_next > b + 0.3:
break
ax3.plot([x_cob, x_cob], [x_cob, x_next], 'g-', alpha=0.5, linewidth=1)
ax3.plot([x_cob, x_next], [x_next, x_next], 'g-', alpha=0.5, linewidth=1)
x_cob = x_next
ax3.plot(x_cob, x_cob, 'rs', markersize=8, zorder=6)
setup_ax(ax3, "Not a contraction: $|g'| > 1$\ncobweb diverges from central fixed point")
plt.tight_layout()
plt.show()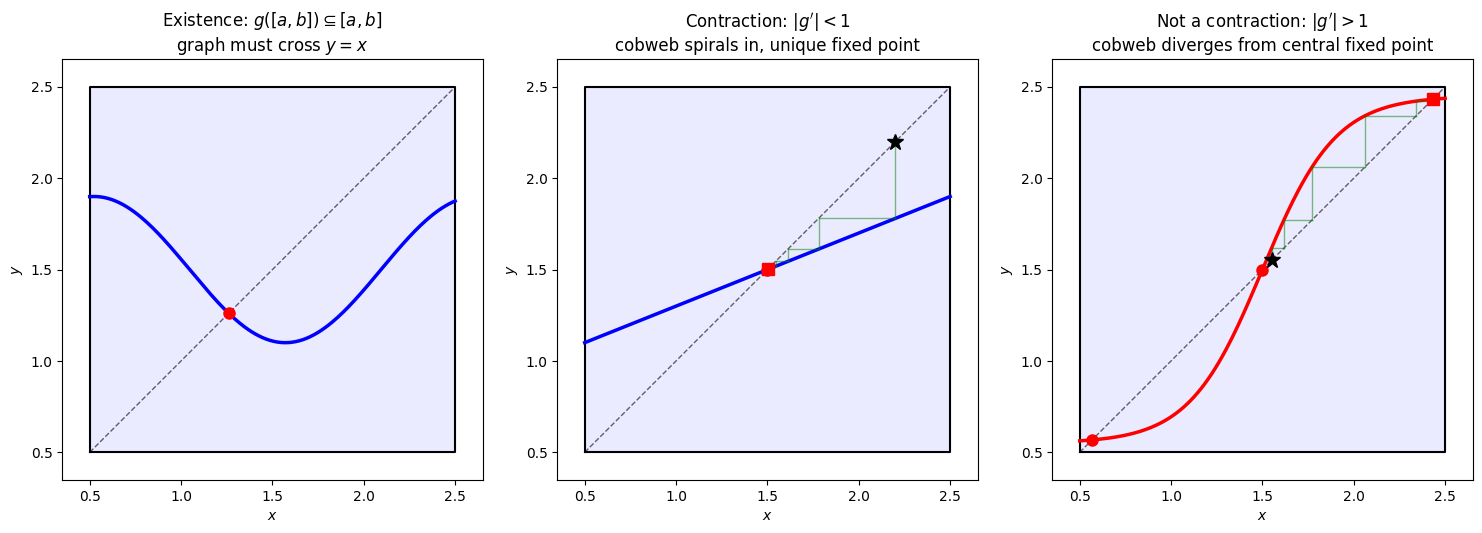
Geometric intuition for fixed point iteration. In the cobweb diagrams (center and right), the black star () marks the starting point and the red square marks the final iterate. Left: If maps into itself, its graph stays inside the blue box and must cross the diagonal at least once, guaranteeing existence of a fixed point. Center: When everywhere on , the graph is less steep than the diagonal, so there is exactly one crossing. The cobweb diagram shows the iteration spiraling inward from the start () to the unique fixed point. Right: When but near the center, the graph is steep enough to cross the diagonal multiple times, creating three fixed points. The cobweb starting near the central (unstable) fixed point () diverges away from it, eventually settling at one of the stable outer fixed points where .
Theorem 1 (Fixed Point Existence, Uniqueness, and Convergence)
Given continuous:
Existence: If maps into itself (i.e., ), then has at least one fixed point in .
Uniqueness: If additionally for all , then the fixed point is unique.
Convergence: Under the same conditions, for any , the sequence converges to the unique fixed point , and the convergence is geometric:
Proof 1 (Existence)
Define .
If or , we’re done. We’ve found a fixed point.
Otherwise, since :
, so
, so
By the Intermediate Value Theorem, there exists with , i.e., .
Proof 2 (Uniqueness)
Suppose two fixed points exist. By the Mean Value Theorem:
for some .
This implies . But and , so . This is a contradiction.
Proof 3 (Convergence)
Remark 1 (Understanding Geometric Convergence)
The bound is called geometric (or linear) convergence. At each step, the error is multiplied by at most :
The value of , called the contraction factor, controls the speed:
close to 0: fast convergence (each step eliminates most of the error).
close to 1: painfully slow (each step barely improves the approximation).
: no convergence guarantee.
Taking logarithms of the error bound gives , so geometric convergence appears as a straight line on a log-scale plot, with slope . Smaller means a steeper downward slope.
import numpy as np
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(8, 4.5))
n = np.arange(0, 30)
e0 = 1.0
for rho, color, style in [(0.9, '#d62728', '-'),
(0.7, '#ff7f0e', '-'),
(0.5, '#2ca02c', '-'),
(0.2, '#1f77b4', '-')]:
errors = e0 * rho**n
ax.semilogy(n, errors, style, color=color, linewidth=2,
marker='o', markersize=3,
label=rf'$\rho = {rho}$ (slope $\log_{{10}}\rho = {np.log10(rho):.2f}$)')
ax.set_xlabel('Iteration $n$', fontsize=12)
ax.set_ylabel('Error bound $\\rho^n |e_0|$', fontsize=12)
ax.set_title('Geometric convergence: smaller $\\rho$ = steeper descent on log scale')
ax.legend(fontsize=10)
ax.grid(True, alpha=0.3, which='both')
ax.set_xlim(0, 29)
ax.set_ylim(1e-15, 2)
plt.tight_layout()
plt.show()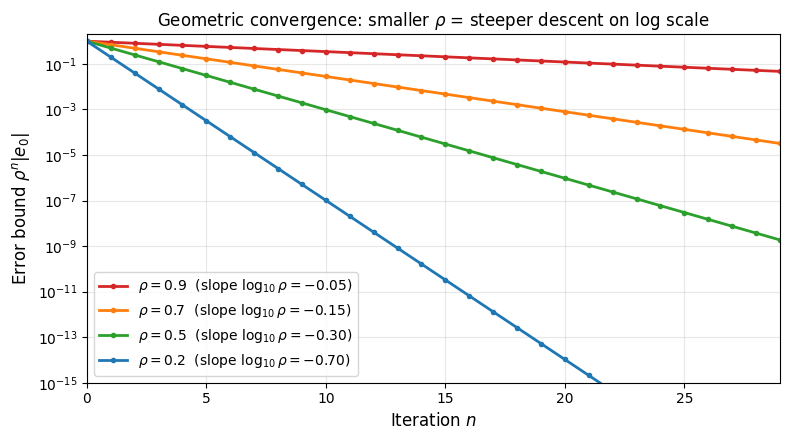
Bounding the Forward Error from the Step Size¶
The convergence proof shows that . This means the steps are shrinking geometrically. We can use this to bound how far is from the true fixed point , even though we don’t know .
Lemma 1 (Step Size Bounds the Forward Error)
Proof 4
This justifies the stopping test used in our algorithms. If the step test is satisfied, the lemma guarantees:
When is small (fast convergence), and the forward error is close to . When is close to 1 (slow convergence), the factor can be large and the step test becomes unreliable.
The Derivative at the Fixed Point¶
The key insight: determines everything.
For our three reformulations of :
: We have , so . Right on the boundary, so no convergence is guaranteed (and indeed, it fails).
: We have , so . Linear convergence with rate .
: We have , so . The derivative vanishes! When , the convergence is faster than linear — in fact, it is quadratic, meaning the number of correct digits doubles at every step. We’ll explore this in detail in Newton’s Method, since is Newton’s method for this problem.
The design principle: make as small as possible. The optimal choice is , which is exactly what Newton’s method achieves by setting .
The Banach Fixed Point Theorem¶
Optional: a look ahead. The convergence results above are special cases of a far more general principle. This section is not required for what follows, but it gives a glimpse of why the same contraction idea appears in so many areas of mathematics.
The convergence results above are special cases of a fundamental principle that appears throughout mathematics.
Theorem 2 (Banach Fixed Point Theorem)
Let be a complete metric space and be a contraction:
for some . Then:
has a unique fixed point
The iteration converges from any starting point
Convergence is geometric:
Remark 2 (Why the Banach FPT Matters)
The power of this theorem is in the generality of the space . A complete metric space is any space with a notion of distance where Cauchy sequences converge. This includes:
with the Euclidean distance (our setting here)
Function spaces like with the sup-norm
Probability spaces like the space of distributions with the Wasserstein distance
Sequence spaces like with the -norm
In each of these spaces, the Banach FPT gives existence, uniqueness, and convergence in one shot. The same principle governs:
Newton’s method for systems: The iteration is a contraction near the solution
Picard iteration for ODEs: Proves existence and uniqueness for by showing the integral operator is a contraction on
Iterative linear solvers: Jacobi and Gauss-Seidel converge when the iteration matrix is a contraction on
Whenever you see an iterative method that “works,” there is often a contraction hiding underneath.