This section is optional reading. It leans more heavily on linear algebra than the rest of the chapter and is not required by anything that follows.
The least squares problem arises whenever a linear system is not exactly solvable. There are two cases: overdetermined (, too many equations) and underdetermined (, too few equations). Both are understood through the fundamental subspaces of .
The Fundamental Subspaces¶
Given with rank , the matrix maps between two spaces that each split into orthogonal pairs:
The matrix maps the row space onto the range (an isomorphism when restricted to these subspaces), and sends the kernel to zero.
import numpy as np
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(10, 5.5))
from matplotlib.patches import Polygon
s = 0.9 # half-diagonal of range/row space diamonds
sn = 0.55 # half-diagonal of null space diamonds (smaller)
def diamond(cx, cy, s):
"""Vertices of a square rotated 45 degrees, centered at (cx, cy)."""
return np.array([[cx + s, cy], [cx, cy + s], [cx - s, cy], [cx, cy - s]])
left_cx, right_cx = -2.5, 2.5
# Left pair: R(A^T) below, N(A) above, meeting at the shared corner
# N(A) diamond centered at (left_cx, -sn), top corner at (left_cx, 0)
null_verts = diamond(left_cx, -sn, sn)
ax.add_patch(Polygon(null_verts, facecolor='#d62728', alpha=0.15,
edgecolor='#d62728', lw=2))
ax.text(left_cx, -sn-0.1, r'$\mathrm{N}(A)$', ha='center', va='center',
fontsize=12, color='#d62728', fontweight='bold')
ax.text(left_cx - sn - 0.1, -sn, 'dim $n{-}r$', ha='right', fontsize=9, color='#d62728')
# R(A^T) diamond centered at (left_cx, +s), bottom corner at (left_cx, 0)
row_verts = diamond(left_cx, s, s)
ax.add_patch(Polygon(row_verts, facecolor='#1f77b4', alpha=0.2,
edgecolor='#1f77b4', lw=2))
ax.text(left_cx, s, r'$\mathrm{R}(A^T)$', ha='center', va='center',
fontsize=13, color='#1f77b4', fontweight='bold')
ax.text(left_cx - s - 0.1, s, 'dim $r$', ha='right', fontsize=10, color='#1f77b4')
# Label
ax.text(left_cx, 2*s + 0.25, r'$\mathbb{R}^n$',
ha='center', fontsize=14, fontweight='bold')
# Right pair: R(A) below, N(A^T) above, meeting at the shared corner
coker_verts = diamond(right_cx, -sn, sn)
ax.add_patch(Polygon(coker_verts, facecolor='#ff7f0e', alpha=0.15,
edgecolor='#ff7f0e', lw=2))
ax.text(right_cx, -sn-0.1, r'$\mathrm{N}(A^T)$', ha='center', va='center',
fontsize=12, color='#ff7f0e', fontweight='bold')
ax.text(right_cx + sn + 0.1, -sn, 'dim $m{-}r$', ha='left', fontsize=9, color='#ff7f0e')
range_verts = diamond(right_cx, s, s)
ax.add_patch(Polygon(range_verts, facecolor='#2ca02c', alpha=0.2,
edgecolor='#2ca02c', lw=2))
ax.text(right_cx, s, r'$\mathrm{R}(A)$', ha='center', va='center',
fontsize=13, color='#2ca02c', fontweight='bold')
ax.text(right_cx + s + 0.15, s, 'dim $r$', ha='left', fontsize=10, color='#2ca02c')
# Label
ax.text(right_cx, 2*s + 0.25, r'$\mathbb{R}^m$',
ha='center', fontsize=14, fontweight='bold')
# Arrow: A maps R(A^T) -> R(A)
ax.annotate('', xy=(right_cx - s - 0.15, 2*s + 0.25),
xytext=(left_cx + s + 0.15, 2*s + 0.25),
arrowprops=dict(arrowstyle='->', lw=2.5, color='black'))
ax.text(0, 2*s + 0.45, '$A$', ha='center', fontsize=15, fontweight='bold')
# Projections at midpoints of left faces of each diamond
# R(A) diamond: center (right_cx, s), left face midpoint is halfway
# between left vertex (right_cx - s, s) and bottom vertex (right_cx, 0)
proj_range = np.array([right_cx - s/2, s/2])
# N(A^T) diamond: center (right_cx, -sn), left face midpoint is halfway
# between top vertex (right_cx, 0) and left vertex (right_cx - sn, -sn)
proj_coker = np.array([right_cx - sn/2, -sn + sn/2])
# b = proj_range + proj_coker (relative to origin of right pair)
# Place b at the sum of the two projection vectors (relative to right_cx, 0)
b_pos = proj_range + proj_coker - np.array([right_cx, 0])
ax.plot(b_pos[0], b_pos[1], 'ko', markersize=6, zorder=5)
ax.text(b_pos[0] - 0.25, b_pos[1], r'$\mathbf{b}$', ha='right', va='center',
fontsize=14, fontweight='bold')
# Dashed line from b to projection in R(A)
ax.plot([b_pos[0], proj_range[0]], [b_pos[1], proj_range[1]],
'--', color='#2ca02c', lw=1.5, alpha=0.7)
ax.plot(proj_range[0], proj_range[1], 'o', color='#2ca02c', markersize=5, zorder=5)
ax.text(proj_range[0] + 0.15, proj_range[1], r'$\tilde{\mathbf{b}}$',
fontsize=12, color='#2ca02c', ha='center')
# Dashed line from b to projection in N(A^T)
ax.plot([b_pos[0], proj_coker[0]], [b_pos[1], proj_coker[1]],
'--', color='#ff7f0e', lw=1.5, alpha=0.7)
ax.plot(proj_coker[0], proj_coker[1], 'o', color='#ff7f0e', markersize=5, zorder=5)
ax.text(proj_coker[0] + 0.1, proj_coker[1] - 0.18, r'$\mathbf{r}$',
fontsize=11, color='#ff7f0e', ha='center')
# Same construction on the left: x = x_row + x_null
proj_row = np.array([left_cx + s/2, s/2])
proj_null = np.array([left_cx + sn/2, -sn + sn/2])
x_pos = proj_row + proj_null - np.array([left_cx, 0])
ax.plot(x_pos[0], x_pos[1], 'ko', markersize=6, zorder=5)
ax.text(x_pos[0] + 0.25, x_pos[1], r'$\mathbf{x}$', ha='left', va='center',
fontsize=14, fontweight='bold')
ax.plot([x_pos[0], proj_row[0]], [x_pos[1], proj_row[1]],
'--', color='#1f77b4', lw=1.5, alpha=0.7)
ax.plot(proj_row[0], proj_row[1], 'o', color='#1f77b4', markersize=5, zorder=5)
ax.text(proj_row[0] - 0.12, proj_row[1] + 0.04, r'$\mathbf{x}_r$',
fontsize=12, color='#1f77b4', ha='center')
ax.plot([x_pos[0], proj_null[0]], [x_pos[1], proj_null[1]],
'--', color='#d62728', lw=1.5, alpha=0.7)
ax.plot(proj_null[0], proj_null[1], 'o', color='#d62728', markersize=5, zorder=5)
ax.text(proj_null[0] - 0.1, proj_null[1] - 0.15, r'$\mathbf{x}_n$',
fontsize=11, color='#d62728', ha='center')
# Curved arrow showing A: x_r in R(A^T) maps to tilde b = A x_hat in R(A)
from matplotlib.patches import FancyArrowPatch
arrow = FancyArrowPatch(proj_row, proj_range,
connectionstyle='arc3,rad=-0.35',
arrowstyle='->', mutation_scale=15,
color='black', lw=1.5, alpha=0.8)
ax.add_patch(arrow)
arrow_x = FancyArrowPatch(x_pos, proj_range,
connectionstyle='arc3,rad=-0.35',
arrowstyle='->', mutation_scale=15,
color='black', lw=1.5, alpha=0.8)
ax.add_patch(arrow_x)
ax.text(0, (proj_row[1] + proj_range[1]) / 2 + 0.55, r'$A$',
ha='center', fontsize=12, fontweight='bold')
ax.set_xlim(-4.5, 4.5)
ax.set_ylim(-2.2, 2.8)
ax.set_aspect('equal')
ax.axis('off')
plt.tight_layout()
plt.show()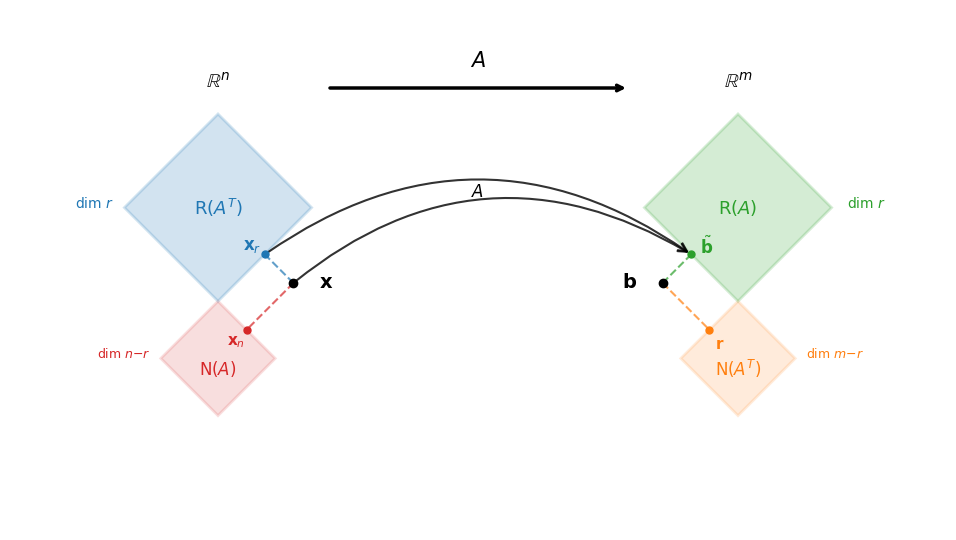
The Two Types of Least Squares¶
Overdetermined: (too many equations)¶
The system has no exact solution because generally does not lie in . We minimize the residual:
The solution projects onto : decompose where the residual is orthogonal to the range. When has full column rank (), the kernel is trivial and is unique.
Underdetermined: (too few equations)¶
The system has infinitely many solutions (when ). We pick the minimum norm solution:
The solution projects onto : any solution can be written as with . The minimum norm solution is the unique one with no kernel component, i.e., .
In this course we focus on the overdetermined case (, full column rank).
Geometric Interpretation¶
The least squares solution projects onto . The decomposition splits into:
The residual lies in the cokernel , which is the orthogonal complement of (right panel above). This orthogonality condition characterizes the least squares solution.
The Two Types of Least Squares¶
Depending on the rank of , there are two distinct situations:
Case 1: Full column rank ()¶
The kernel is trivial, so the least squares solution is unique. The problem reduces to projecting onto (the cokernel projection). This is the standard overdetermined case.
Case 2: Rank-deficient ()¶
The kernel is nontrivial: if is a least squares solution, then so is for any . Among all least squares solutions, we pick the minimum norm solution: the unique that lies in (i.e., has no component in ). This requires the SVD or pseudoinverse to compute.
In this course we focus on Case 1 (full column rank).
Solving Least Squares via QR¶
Let be the full QR decomposition, where is orthogonal and . Partition:
where (the first columns), , and is upper triangular. The reduced (thin) QR factorization is .
Theorem 1 (QR Solution to Least Squares)
Proof 1
Perturbation Theory for Least Squares¶
Before choosing an algorithm, we ask how sensitive the solution is to perturbations in the data and . Unlike square systems, the answer depends not only on but also on the size of the residual.
Recall the 2-norm condition number of a tall full-rank matrix:
where is the pseudoinverse.
Theorem 2 (Least Squares Perturbation Bound)
Remark 1 (Reading the Bound)
Two regimes deserve attention.
Small residual (, nearly in ). Then and the bound collapses to . The least squares problem is as well conditioned as a square linear system.
Large residual ( not small). The term dominates. Sensitivity scales with the square of the condition number, even when itself is only mildly ill conditioned.
This term is the central obstruction in least squares.
Remark 2 (Why This Rules Out the Normal Equations)
Forming produces a square system with condition number
Solving it by Cholesky in finite precision incurs a relative error of order regardless of the residual. QR instead works directly with and inherits only the intrinsic conditioning from Theorem 2. Comparing the two:
Small residual (): the problem is conditioned. QR delivers that. Normal equations still pay , so they are strictly worse, sometimes catastrophically.
Large residual: the problem itself is already conditioned. Normal equations are no worse than the inherent sensitivity; QR offers no accuracy advantage here.
The asymmetry is the point: QR is never worse and is much better whenever the residual is small, which is the typical regime for a well-posed fitting problem.
Algorithm¶
The QR-based algorithm is:
Factor: compute via Householder
Transform: compute
Solve: back substitution on
Since we never form , the effective condition number is rather than in the small-residual regime.
Remark 3 (Normal Equations)
An alternative derivation uses the orthogonality condition directly to obtain (the normal equations). While mathematically equivalent, solving the normal equations is numerically dangerous because (exercise).
Linear Regression¶
The most common application of least squares is fitting a model to data.
Example 1 (Polynomial Fitting)
Given data points , fit a polynomial :
With data points, this system is overdetermined. Solve via QR: compute , then .