The QR factorization decomposes any matrix into an orthogonal matrix times an upper triangular matrix. Householder reflections provide a numerically stable way to compute it, the gold standard for numerical linear algebra.
The QR Factorization¶
Definition 1 (QR Factorization)
Theorem 1 (Existence and Uniqueness of QR)
Every with has a QR factorization.
If has full column rank, the reduced QR is unique (up to signs of columns of ) when we require to have positive diagonal entries.
Proof 1
The Gram-Schmidt algorithm constructs an orthonormal basis for the column space of and expresses each column as a linear combination of :
where for and . In matrix form this is with orthogonal and upper triangular.
Uniqueness: if with positive diagonals, then is both orthogonal and upper triangular, hence a diagonal matrix with entries. The positive diagonal constraint forces it to be .
Computing QR: Householder Reflections¶
Gram-Schmidt constructs QR by orthogonalizing columns via subtraction, which is numerically unstable (see loss of orthogonality). The stable alternative is the same idea as column elimination in Gaussian elimination, with one substitution: instead of eliminating below the diagonal by subtracting multiples of rows (recorded as triangular factors ), we eliminate by applying orthogonal reflectors that zero entries below the diagonal of each column. The triangular factors of GE are cheap but can amplify errors; the orthogonal reflectors of Householder preserve norms and do not.
Concretely, we triangularize by multiplying with orthogonal matrices:
Each is a Householder reflector that zeros out entries below the diagonal in column .
Householder Reflectors¶
Definition 2 (Householder Reflector)
Given a unit vector , the Householder reflector is:
This matrix reflects any vector across the hyperplane perpendicular to .
Proposition 1 (Properties of Householder Reflectors)
A Householder reflector satisfies:
is symmetric:
is orthogonal:
is an involution:
reflects across the hyperplane
Proof 2
(1) since .
(2) since .
(3) Follows from (2) and .
(4) Decompose . The first term is the component along , the second is in the hyperplane. Then : the component along is negated.
import numpy as np
import matplotlib.pyplot as plt
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# Left: reflection of a single vector
ax = axes[0]
v = np.array([1, 1]) / np.sqrt(2) # reflection normal
x = np.array([2, 0.5])
H = np.eye(2) - 2 * np.outer(v, v)
Hx = H @ x
# Hyperplane (perpendicular to v)
perp = np.array([-v[1], v[0]])
t = np.linspace(-2.5, 2.5, 100)
ax.plot(t * perp[0], t * perp[1], 'k-', lw=1, alpha=0.4, label='hyperplane')
# Vectors
ax.annotate('', xy=x, xytext=[0, 0],
arrowprops=dict(arrowstyle='->', color='#1f77b4', lw=2))
ax.annotate('', xy=Hx, xytext=[0, 0],
arrowprops=dict(arrowstyle='->', color='#d62728', lw=2))
ax.annotate('', xy=v * 1.5, xytext=[0, 0],
arrowprops=dict(arrowstyle='->', color='gray', lw=1.5, ls='--'))
# Dashed line showing reflection
ax.plot([x[0], Hx[0]], [x[1], Hx[1]], 'k:', lw=1, alpha=0.5)
ax.text(x[0] + 0.1, x[1] + 0.1, r'$\mathbf{x}$', fontsize=13, color='#1f77b4')
ax.text(Hx[0] + 0.1, Hx[1] - 0.25, r'$H\mathbf{x}$', fontsize=13, color='#d62728')
ax.text(v[0] * 1.5 + 0.1, v[1] * 1.5 + 0.1, r'$\mathbf{v}$', fontsize=13, color='gray')
ax.set_xlim(-2.5, 2.5)
ax.set_ylim(-2.5, 2.5)
ax.set_aspect('equal')
ax.grid(True, alpha=0.3)
ax.set_title(r'Householder reflection: $H = I - 2\mathbf{v}\mathbf{v}^T$')
# Right: choosing v to map x to ||x||e1
ax = axes[1]
x2 = np.array([1.5, 2.0])
norm_x = np.linalg.norm(x2)
target = norm_x * np.array([1, 0])
# Householder vector
v2 = x2 - target
v2 = v2 / np.linalg.norm(v2)
H2 = np.eye(2) - 2 * np.outer(v2, v2)
Hx2 = H2 @ x2
# Hyperplane
perp2 = np.array([-v2[1], v2[0]])
ax.plot(t * perp2[0], t * perp2[1], 'k-', lw=1, alpha=0.4, label='hyperplane')
ax.annotate('', xy=x2, xytext=[0, 0],
arrowprops=dict(arrowstyle='->', color='#1f77b4', lw=2))
ax.annotate('', xy=Hx2, xytext=[0, 0],
arrowprops=dict(arrowstyle='->', color='#d62728', lw=2))
# Show that ||x|| = ||Hx|| (circle)
theta = np.linspace(0, 2 * np.pi, 100)
ax.plot(norm_x * np.cos(theta), norm_x * np.sin(theta), 'k:', lw=0.8, alpha=0.3)
ax.text(x2[0] + 0.1, x2[1] + 0.1, r'$\mathbf{x}$', fontsize=13, color='#1f77b4')
ax.text(Hx2[0] + 0.1, Hx2[1] - 0.25, r'$H\mathbf{x} = \|\mathbf{x}\|\mathbf{e}_1$',
fontsize=12, color='#d62728')
ax.set_xlim(-1, 3)
ax.set_ylim(-2, 2.5)
ax.set_aspect('equal')
ax.grid(True, alpha=0.3)
ax.set_title(r'Choosing $\mathbf{v}$ to map $\mathbf{x} \to \|\mathbf{x}\|\mathbf{e}_1$')
plt.tight_layout()
plt.show()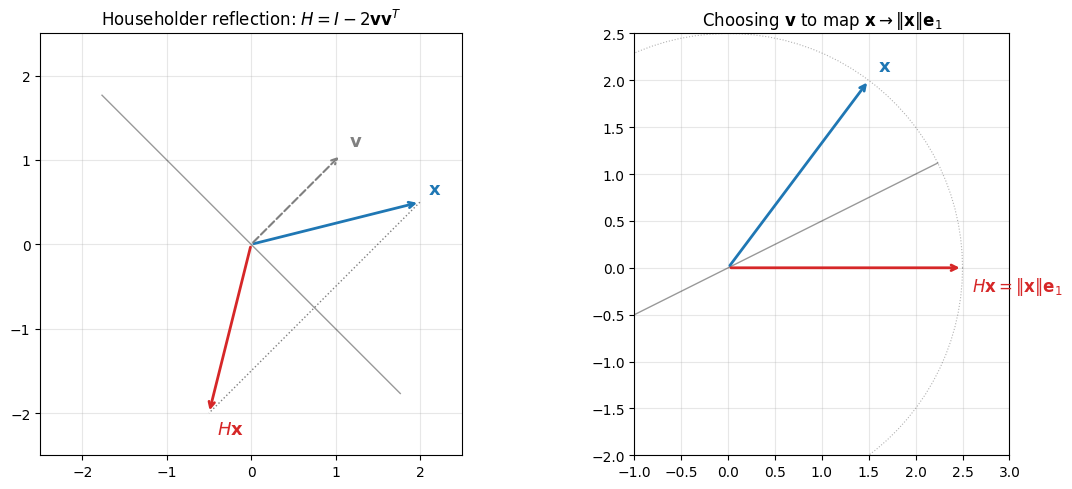
Computing the Householder Vector¶
To zero out everything below the first entry of a vector , we need . Since is a reflection and preserves norms, the target lies on the same sphere as (right panel above). The Householder vector is the bisector of and the target:
The sign choice avoids cancellation when is nearly parallel to .
The Algorithm¶
Algorithm 1 (Householder QR)
Input:
Output: Orthogonal and upper triangular with
for :
Let (the subcolumn below the diagonal)
,
Note that step 4 applies the reflection only to the submatrix, and the matrix-vector product avoids forming explicitly.
For , the factorization costs flops; forming explicitly costs an additional , while applying to a single vector costs only . In the square case , the factorization cost reduces to flops, twice the cost of LU factorization. For least squares we usually do not need explicitly, just , which can be computed by applying the Householder reflectors sequentially.
Numerical Stability¶
We developed the framework of forward and backward stability in the previous chapter. Recall that forward stability is unattainable (Proposition 2), and the right standard is backward stability: the computed result is the exact result for a slightly perturbed input. Householder QR achieves this.
What does this mean for a factorization? The algorithm takes and returns computed factors . These will not satisfy exactly. Backward stability asks for the next best thing: there exists a small perturbation such that exactly. In other words, the computed factors are the exact QR factorization of a nearby matrix. The size of is the backward error, and we want .
Theorem 2 (Backward Stability of Householder QR)
Proof 3
(Sketch, following Higham, Accuracy and Stability of Numerical Algorithms, Ch. 19.)
The full proof tracks rounding errors through each Householder step. We outline the three key ingredients and how they combine.
Step 1: One Householder reflection is backward stable.
At step , we apply a Householder reflector to the current matrix. The key operation is for a submatrix . In floating point, the computed result satisfies
To see why is small, look at how is actually computed. The two intermediate quantities are the row vector and the rank-one update . Apply the standard floating-point error model:
is a row of dot products. Each computed entry satisfies for a small constant . Since , this is .
The subtraction adds another per entry from the multiply-add.
Collecting both, the computed result equals with . The constant does not depend on because and does not stretch any direction.
Contrast this with Gaussian elimination. The elementary matrix contains the multipliers , which can be arbitrarily large when is small. The analogous bound there carries a factor, which is exactly the growth factor that pivoting tries to control. Orthogonal has unconditionally, so no such amplification appears.
Step 2: The perturbations compose additively, not multiplicatively.
After steps, the computed upper triangular factor satisfies
We claim the perturbed product equals with , where . The key point is the , not .
Start with two factors. Writing with ,
The last term is and we drop it. The two first-order terms each contain a single flanked by orthogonal factors. Since , the flanking does not change the size: , and likewise for the other term. The total error is bounded by , the sum of the factor errors rather than a product.
If were not orthogonal the sandwich would scale by , and with factors the analogous bound carries a amplification. Orthogonality is exactly what kills this multiplicative blow-up.
Extending to factors gives the same conclusion: each of the first-order terms is a single flanked by orthogonal matrices, contributing , so the total is .
Step 3: Rewriting as a backward error on .
The computed is implicitly defined as the inverse of the product of computed reflectors: . Transposing, . Substituting into and using from Step 2,
where we used . Setting , the relative backward error satisfies
since .
Takeaway. The proof works because orthogonal matrices have three properties that prevent error growth: unit norm (, no amplification), norm preservation (, no cancellation), and unit condition number (, perturbations stay small under composition).
The orthogonality of the computed is the key difference from Gram-Schmidt. For Gram-Schmidt, the loss of orthogonality is , which can be catastrophic for ill-conditioned matrices. Householder maintains regardless of conditioning.
Why Orthogonal Transformations Are Ideal¶
The stability of Householder QR is not accidental. It reflects a deeper principle: errors under composition of orthogonal matrices add, they do not multiply.
For a single orthogonal this is obvious. If carries an error , then
The error is transported, never magnified. The composition property is the consequence we cashed in during Step 2 of Theorem 2. The perturbed product expands to
For orthogonal each summand has norm because the flanking factors have unit norm, so the total first-order error is bounded by
For general invertible factors the same expansion holds, but the sandwich inequality gives
so the total error is bounded by
multiplicative in the factor norms. If each , this is , the exponential blow-up that orthogonality avoids.
This is why orthogonal transformations are the tool of choice throughout numerical linear algebra, from QR factorization to eigenvalue algorithms: they are the only family of matrices for which long sequences of operations do not amplify rounding errors.
Solving Linear Systems with QR¶
Given a square system with invertible, the QR factorization reduces it to a triangular solve:
The steps are:
Factor: compute via Householder ( flops for square )
Transform: compute ( flops)
Solve: back substitution on ( flops)
Example 1 (Solving a Linear System with QR)
Compared to LU, the QR approach costs roughly twice as many flops ( for QR vs for LU). For square systems where stability is not a concern, LU is preferred. The real advantage of QR appears for least squares problems, where the system is overdetermined and LU does not apply.