This notebook demonstrates fixed point iteration for solving nonlinear equations, showing how convergence depends on the choice of iteration function .
import numpy as np
import matplotlib.pyplot as pltThe Problem: Finding ¶
We want to solve , i.e., find .
Fixed point iteration rewrites this as and iterates .
Key question: How does the choice of affect convergence?
# True root
x_true = np.sqrt(3)
def fixed_point_iteration(g, x0, max_iter=20, tol=1e-12):
"""Run fixed point iteration and return history."""
history = [(0, x0, abs(x0 - x_true))]
x = x0
for n in range(1, max_iter + 1):
try:
x_new = g(x)
error = abs(x_new - x_true)
history.append((n, x_new, error))
if abs(x_new - x) < tol:
break
x = x_new
except:
break
return history
def print_history(history, name):
"""Print iteration history."""
print(f"\n{name}:")
print(f"{'n':>3} | {'x_n':>14} | {'Error':>12}")
print("-" * 35)
for n, x, err in history[:8]:
print(f"{n:3d} | {x:14.10f} | {err:12.2e}")
if len(history) > 8:
print("...")
n, x, err = history[-1]
print(f"{n:3d} | {x:14.10f} | {err:12.2e}")g1 = lambda x: 3.0 / x
history1 = fixed_point_iteration(g1, x0=1.25, max_iter=10)
print_history(history1, "g₁(x) = 3/x")
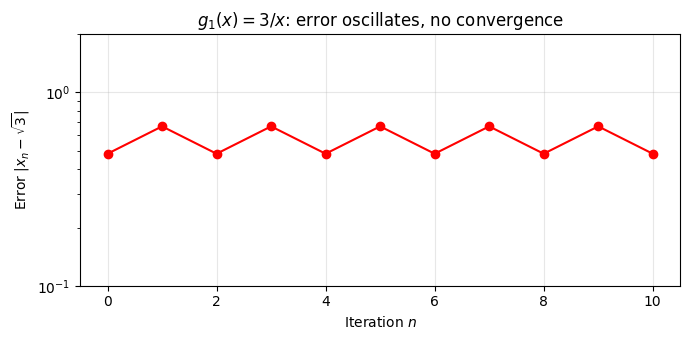
print(f"\n|g₁'(√3)| = {abs(-3/3):.2f} — oscillates without converging!")
# Convergence plot
fig, ax = plt.subplots(figsize=(7, 3.5))
errors1 = [e for _, _, e in history1]
ax.semilogy(range(len(errors1)), errors1, 'ro-', markersize=6)
ax.set_xlabel('Iteration $n$')
ax.set_ylabel(r'Error $|x_n - \sqrt{3}|$')
ax.set_title(r'$g_1(x) = 3/x$: error oscillates, no convergence')
ax.grid(True, alpha=0.3)
ax.set_ylim(1e-1, 2)
plt.tight_layout()
plt.show()
g₁(x) = 3/x:
n | x_n | Error
-----------------------------------
0 | 1.2500000000 | 4.82e-01
1 | 2.4000000000 | 6.68e-01
2 | 1.2500000000 | 4.82e-01
3 | 2.4000000000 | 6.68e-01
4 | 1.2500000000 | 4.82e-01
5 | 2.4000000000 | 6.68e-01
6 | 1.2500000000 | 4.82e-01
7 | 2.4000000000 | 6.68e-01
...
10 | 1.2500000000 | 4.82e-01
|g₁'(√3)| = 1.00 — oscillates without converging!
Example 2: (Slow Convergence)¶
This comes from a gradient descent-style approach.
We have , so . Converges, but slowly.
g2 = lambda x: x - 0.5 * (x**2 - 3)
history2 = fixed_point_iteration(g2, x0=1.25, max_iter=50)
print_history(history2, "g₂(x) = x - (x² - 3)/2")
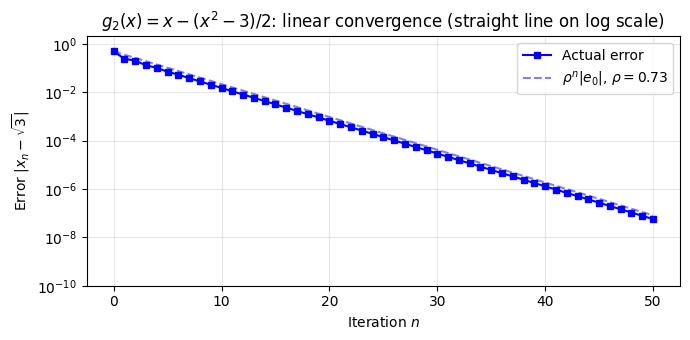
rho2 = abs(1 - x_true)
print(f"\n|g₂'(√3)| = {rho2:.4f} — linear convergence")
# Convergence plot
fig, ax = plt.subplots(figsize=(7, 3.5))
errors2 = [e for _, _, e in history2]
n2 = np.arange(len(errors2))
ax.semilogy(n2, errors2, 'bs-', markersize=4, label='Actual error')
ax.semilogy(n2, errors2[0] * rho2**n2, 'b--', alpha=0.5,
label=rf'$\rho^n |e_0|$, $\rho = {rho2:.2f}$')
ax.set_xlabel('Iteration $n$')
ax.set_ylabel(r'Error $|x_n - \sqrt{3}|$')
ax.set_title(r'$g_2(x) = x - (x^2-3)/2$: linear convergence (straight line on log scale)')
ax.legend()
ax.grid(True, alpha=0.3)
ax.set_ylim(1e-10, 2)
plt.tight_layout()
plt.show()
g₂(x) = x - (x² - 3)/2:
n | x_n | Error
-----------------------------------
0 | 1.2500000000 | 4.82e-01
1 | 1.9687500000 | 2.37e-01
2 | 1.5307617188 | 2.01e-01
3 | 1.8591459990 | 1.27e-01
4 | 1.6309340762 | 1.01e-01
5 | 1.8009610957 | 6.89e-02
6 | 1.6792306616 | 5.28e-02
7 | 1.7693228542 | 3.73e-02
...
50 | 1.7320507510 | 5.66e-08
|g₂'(√3)| = 0.7321 — linear convergence
Example 3: (Fast Convergence)¶
This is the Babylonian method (Newton’s method for square roots).
We have , so .
When , we get quadratic convergence!
g3 = lambda x: 0.5 * (x + 3.0 / x)
history3 = fixed_point_iteration(g3, x0=1.25, max_iter=10)
print_history(history3, "g₃(x) = (x + 3/x)/2 [Babylonian/Newton]")
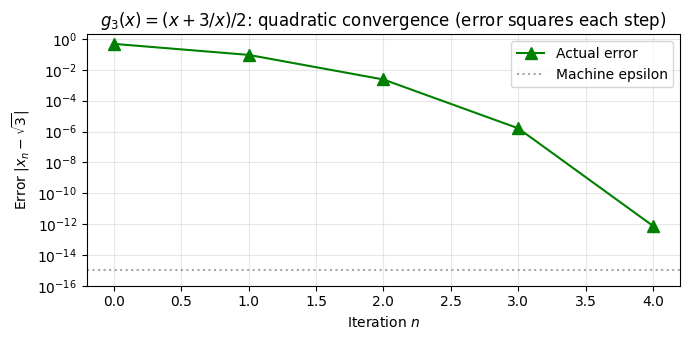
print(f"\ng₃'(√3) = {0.5 * (1 - 3/3):.1f} — quadratic convergence!")
# Convergence plot
fig, ax = plt.subplots(figsize=(7, 3.5))
errors3 = [e for _, _, e in history3 if e > 0]
ax.semilogy(range(len(errors3)), errors3, 'g^-', markersize=8, label='Actual error')
ax.axhline(y=1e-15, color='gray', linestyle=':', alpha=0.7, label='Machine epsilon')
ax.set_xlabel('Iteration $n$')
ax.set_ylabel(r'Error $|x_n - \sqrt{3}|$')
ax.set_title(r"$g_3(x) = (x+3/x)/2$: quadratic convergence (error squares each step)")
ax.legend()
ax.grid(True, alpha=0.3)
ax.set_ylim(1e-16, 2)
plt.tight_layout()
plt.show()
g₃(x) = (x + 3/x)/2 [Babylonian/Newton]:
n | x_n | Error
-----------------------------------
0 | 1.2500000000 | 4.82e-01
1 | 1.8250000000 | 9.29e-02
2 | 1.7344178082 | 2.37e-03
3 | 1.7320524227 | 1.62e-06
4 | 1.7320508076 | 7.53e-13
5 | 1.7320508076 | 0.00e+00
g₃'(√3) = 0.0 — quadratic convergence!
Convergence Comparison¶
Let’s visualize the dramatic difference in convergence rates.
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
# Left: Error vs iteration (all three)
errors1 = [e for _, _, e in history1]
errors2 = [e for _, _, e in history2]
errors3 = [e for _, _, e in history3 if e > 0]
ax1.semilogy(range(len(errors1)), errors1, 'ro-', markersize=6, label=r'$g_1(x) = 3/x$ (diverges)')
ax1.semilogy(range(len(errors2)), errors2, 'bs-', markersize=4, label=r'$g_2(x) = x - (x^2-3)/2$ (linear)')
ax1.semilogy(range(len(errors3)), errors3, 'g^-', markersize=6, label=r'$g_3(x) = (x+3/x)/2$ (quadratic)')
ax1.axhline(y=1e-15, color='gray', linestyle=':', alpha=0.7)
ax1.set_xlabel('Iteration $n$', fontsize=12)
ax1.set_ylabel(r'Error $|x_n - \sqrt{3}|$', fontsize=12)
ax1.set_title('Convergence Comparison', fontsize=14)
ax1.legend(fontsize=9)
ax1.grid(True, alpha=0.3)
ax1.set_ylim(1e-16, 10)
# Right: Cobweb diagram for g3
x = np.linspace(0.5, 2.5, 200)
ax2.plot(x, x, 'k-', linewidth=1, label='$y = x$')
ax2.plot(x, g3(x), 'g-', linewidth=2, label=r'$y = g_3(x)$')
# Cobweb
x_curr = 1.25
for _ in range(5):
x_next = g3(x_curr)
ax2.plot([x_curr, x_curr], [x_curr, x_next], 'b-', alpha=0.6, linewidth=1)
ax2.plot([x_curr, x_next], [x_next, x_next], 'b-', alpha=0.6, linewidth=1)
x_curr = x_next
ax2.plot(x_true, x_true, 'ro', markersize=8, label=r'Fixed point $\sqrt{3}$')
ax2.set_xlabel('$x$', fontsize=12)
ax2.set_ylabel('$y$', fontsize=12)
ax2.set_title('Cobweb Diagram for $g_3$', fontsize=14)
ax2.legend(fontsize=10)
ax2.grid(True, alpha=0.3)
ax2.set_xlim(0.5, 2.5)
ax2.set_ylim(0.5, 2.5)
ax2.set_aspect('equal')
plt.tight_layout()
plt.show()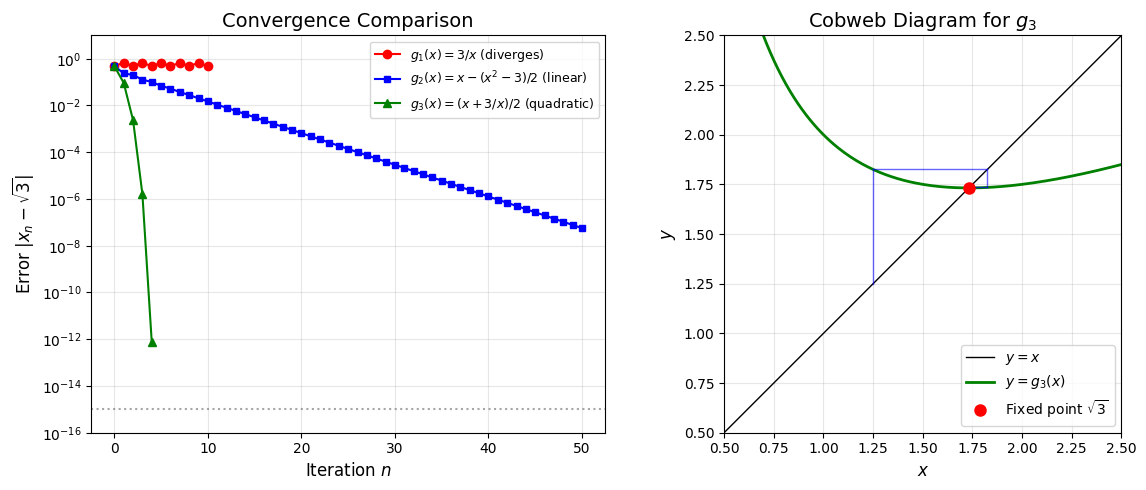
The Role of ¶
The convergence rate depends critically on the derivative at the fixed point:
| Condition | Convergence |
|---|---|
| $ | g’(c) |
| $ | g’(c) |
| $ | g’(c) |
| Quadratic convergence |
Key insight: Newton’s method achieves by construction!
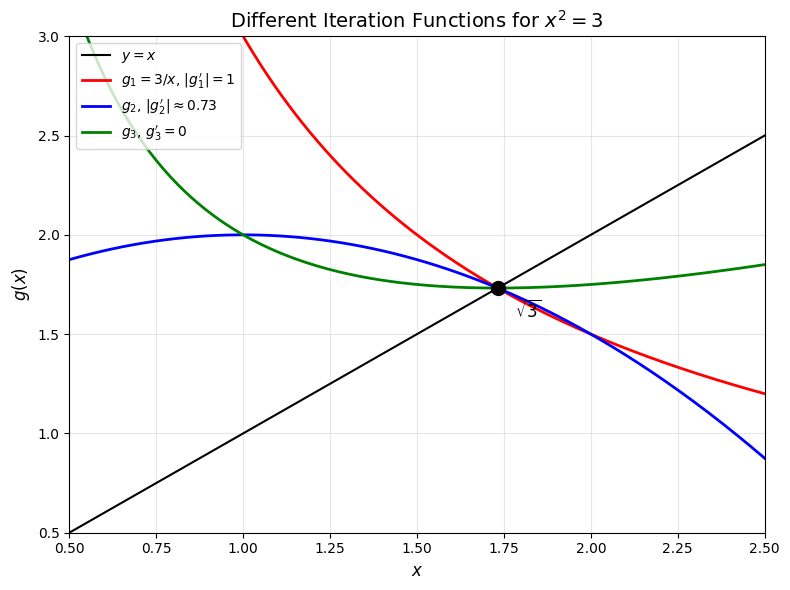
# Visualize derivative condition
fig, ax = plt.subplots(figsize=(8, 6))
x = np.linspace(0.5, 2.5, 200)
ax.plot(x, x, 'k-', linewidth=1.5, label='$y = x$')
ax.plot(x, g1(x), 'r-', linewidth=2, label=r"$g_1 = 3/x$, $|g_1'| = 1$")
ax.plot(x, g2(x), 'b-', linewidth=2, label=r"$g_2$, $|g_2'| \approx 0.73$")
ax.plot(x, g3(x), 'g-', linewidth=2, label=r"$g_3$, $g_3' = 0$")
ax.plot(x_true, x_true, 'ko', markersize=10, zorder=5)
ax.annotate(r'$\sqrt{3}$', (x_true + 0.05, x_true - 0.15), fontsize=12)
ax.set_xlabel('$x$', fontsize=12)
ax.set_ylabel('$g(x)$', fontsize=12)
ax.set_title('Different Iteration Functions for $x^2 = 3$', fontsize=14)
ax.legend(loc='upper left', fontsize=10)
ax.grid(True, alpha=0.3)
ax.set_xlim(0.5, 2.5)
ax.set_ylim(0.5, 3)
plt.tight_layout()
plt.show()