Smoothness is compressibility. The smoother is in physical space, the more localised its Chebyshev (equivalently, Fourier) coefficients are in frequency space, so a handful of coefficients already captures the function to high accuracy. This is one face of the uncertainty principle: what is spread out in is localised in , and vice versa.
Quantitatively: analytic functions give geometric coefficient decay , functions give algebraic decay , and discontinuities give no decay at all and produce Gibbs oscillations that do not vanish as . Reading a coefficient-decay plot is therefore reading the regularity of , and deciding how many coefficients are worth keeping.
Four Representative Functions¶
Before stating any theorem, consider four test functions on chosen so that their regularities span the spectrum from analytic to discontinuous:
is entire: analytic on all of . It has no singularities anywhere in the complex plane.
is real-analytic on but has two complex poles at , sitting close to the real interval.
belongs to : its first and second derivatives are continuous, but the third derivative jumps at .
is discontinuous at . It is of bounded variation but has no derivatives at all in the usual sense.
We compute the Chebyshev interpolant of each at and plot on a log-y axis.
import numpy as np
import matplotlib.pyplot as plt
import scipy.fft as fft
def chebpts(n):
return np.cos(np.pi * np.arange(n+1) / n)
def vals2coeffs(v):
n = len(v) - 1
c = fft.dct(v[::-1], type=1, norm='forward')
c[1:n] *= 2
return c
n = 1024
x = chebpts(n)
fig, axes = plt.subplots(2, 2, figsize=(10, 6.5))
cases = [
(np.sin(5*x), r'$\sin(5x)$ (entire)', 'C0'),
(1/(1 + 25*x**2), r'$1/(1+25x^2)$ (poles at $\pm i/5$)', 'C2'),
(np.abs(x)**3, r'$|x|^3$ ($C^2$)', 'C1'),
(np.sign(x), r'$\mathrm{sign}(x)$ (jump)', 'C3'),
]
for ax, (v, label, color) in zip(axes.flat, cases):
c = vals2coeffs(v)
ax.semilogy(np.abs(c) + 1e-20, '.', ms=3, color=color)
ax.set_title(label)
ax.set_xlabel('$k$'); ax.set_ylabel(r'$|c_k|$')
ax.set_ylim(1e-18, 5)
plt.tight_layout(); plt.show()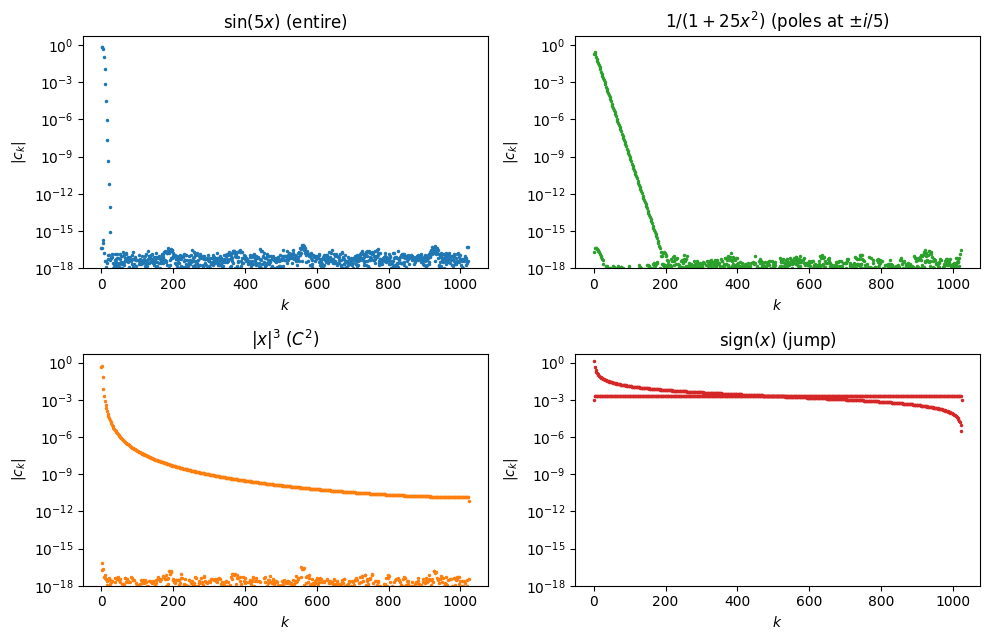
The four panels show qualitatively different behaviour. The two analytic examples decay geometrically, visible as straight lines on the log-y axis, though with very different slopes. The example decays more slowly and curves rather than running straight. The discontinuous sign function barely decays at all. The theorems below explain the rates and when each regime applies.
The Coefficient Decay Theorem¶
For Lipschitz on the Chebyshev series
converges uniformly. The interesting question is how fast.
Both statements of the algebraic theorem below use two regularity notions that are standard in real analysis but deserve a quick reminder.
Definition 1 (Bounded variation and absolute continuity)
A function has bounded variation if
where the supremum ranges over all finite partitions . Intuitively, is the total up-and-down distance that the graph of traces out.
is absolutely continuous on if there exists an integrable function with
This is the derivative at almost every point. Absolute continuity is the regularity class in which the fundamental theorem of calculus holds.
Every absolutely continuous is of bounded variation, with . Every function is absolutely continuous.
Theorem 1 (Algebraic decay)
If are absolutely continuous on and has bounded variation , then for
Proof 1
Sketch. Substituting writes the Chebyshev coefficient as a Fourier cosine integral,
The integrand is the product of the -periodic even function with . One integration by parts gives
and the boundary term vanishes because . So the integral has gained a factor of at the cost of one derivative on . Iterating more times uses the symmetry of across to kill successive boundary terms, and transfers derivatives in total onto . The final step bounds the remaining integrand by the total variation of via a Riemann–Stieltjes estimate. Full details are in Trefethen (2013), Ch. 7.
The in the denominator is a shift that just reflects the finite number of initial indices where the -fold integration by parts has not yet taken hold. For large it is negligible: , and the bound reads , the rate one carries around in practice. For just above the denominator is tiny and the bound is uninformative, but those first few coefficients never drive the approximation error anyway. Once the function is resolved (see the adaptive- algorithm at the end of this chapter), is large enough that the distinction between and disappears into the .
Theorem 2 (Geometric decay)
If is analytic on and extends analytically to the Bernstein ellipse (foci , semi-axis sum ), with there, then
The geometric case is proved by shifting the contour in the defining integral off of and onto in the complex plane; see Trefethen (2013), Ch. 8.
Smoothness Is Compression¶
The decay theorems above have a conceptual payoff worth dwelling on before moving to error bounds. The uncertainty principle says that a function cannot be simultaneously localised in physical space () and in frequency space (). Narrow in one means spread in the other. For Chebyshev (or Fourier) series this is visible: watch the spectrum of a Gaussian bump as we shrink its width .
N = 512
x_nodes = chebpts(N)
xx = np.linspace(-1, 1, 2000)
sigmas = [0.5, 0.1, 0.02]
fig, axes = plt.subplots(len(sigmas), 2, figsize=(10, 2.4 * len(sigmas)))
for i, sigma in enumerate(sigmas):
f_nodes = np.exp(-x_nodes**2 / (2 * sigma**2))
f_plot = np.exp(-xx**2 / (2 * sigma**2))
axes[i, 0].plot(xx, f_plot, 'C0', lw=1.5)
axes[i, 0].set_xlim(-1, 1); axes[i, 0].set_ylim(-0.05, 1.15)
axes[i, 0].set_ylabel('$f(x)$')
axes[i, 0].set_title(rf'bump with $\sigma = {sigma}$')
c = vals2coeffs(f_nodes)
axes[i, 1].semilogy(np.abs(c) + 1e-20, '.', ms=3, color='C3')
axes[i, 1].set_xlim(0, N); axes[i, 1].set_ylim(1e-18, 5)
axes[i, 1].set_ylabel(r'$|c_k|$')
axes[i, 1].set_title('Chebyshev spectrum')
axes[-1, 0].set_xlabel('$x$')
axes[-1, 1].set_xlabel('$k$')
plt.tight_layout(); plt.show()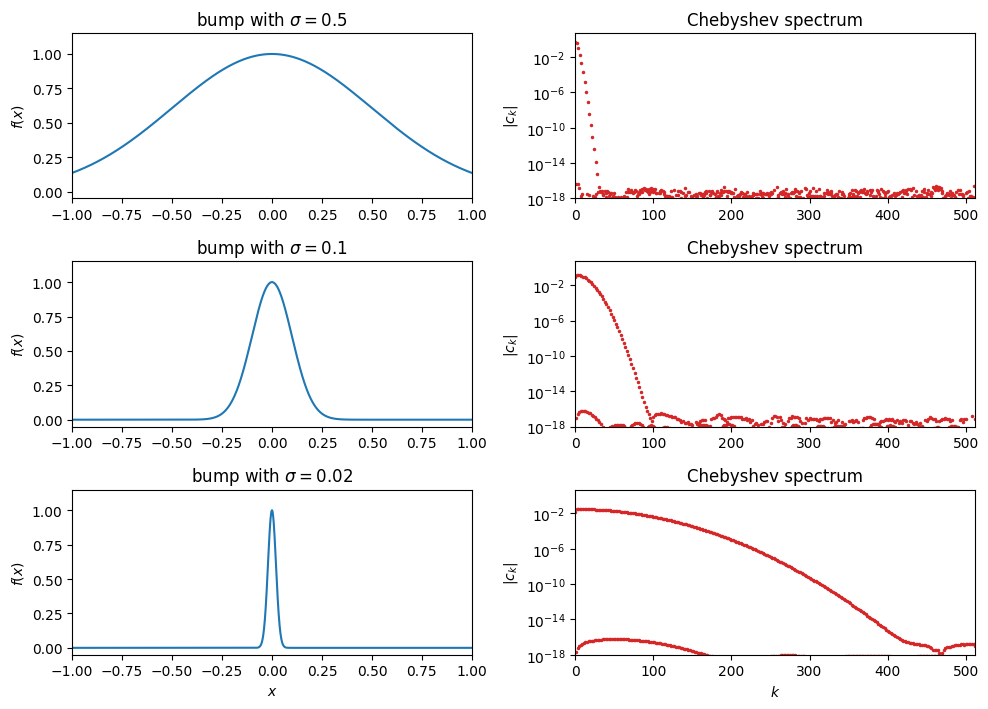
As the bump narrows, its spectrum spreads. A wide, slowly-varying bump () is captured by the first few dozen Chebyshev coefficients. A thin, nearly-delta bump () spreads its coefficients across the full range of we sampled. In the limit the bump becomes a delta and its spectrum is flat, with no compressible tail at all. Concretely, the spatial scale on the left is paired with a spectral scale of order on the right: shrinking by a factor of 25 (from 0.5 to 0.02) spreads the spectrum by roughly the same factor. Localisation in is paid for with spreading in .
Put together with the decay theorems, this is a direct compression picture. The bump-and-spectrum trade-off above was localisation of the function value. The same trade-off applies more generally to features of the function such as its derivatives. The more derivatives has, the less sharp any local feature can be, and the more compressible the spectrum becomes. An analytic on has no sharp features at any order and is captured to machine precision by Chebyshev coefficients, a few dozen numbers for . A function has bounded derivatives up to order but a kink at order , and needs coefficients. A jump is the extreme case: zero width, so the derivative is a delta, and the bump-and-spectrum logic applied to the derivative says the spectrum spreads maximally. Discontinuous functions are not compressible in this basis at all. The concrete picture of this failure mode is the Gibbs phenomenon, which we look at in §The Gibbs Phenomenon after we have the approximation-error bounds in hand.
Where the compression count comes from¶
The coefficient counts above look like estimates on computed quantities, but they are genuinely a priori: they depend only on regularity data about (the Bernstein parameter for analytic , or the derivative order and total variation for functions), not on any computed coefficients. The chain of implication is
Assume regularity of .
Decay theorems Theorem 1 and Theorem 2 bound from the regularity data.
Uniform-error theorem Theorem 3 bounds by the tail .
Sum the tail with the decay bound to get a closed-form error bound as a function of .
Invert: given tolerance , solve for the smallest for which step 4’s bound lies below .
For the analytic case, step 4 gives , and step 5 asks , i.e.
No is ever actually computed in this derivation. We only need and for the function we plan to approximate. The same inversion on the bound from Corollary 1 yields . These are the “compression counts” stated above.
A view from Sobolev theory¶
The same correspondence has a formal home in functional analysis. The cleanest statement is for periodic on with Fourier coefficients , where membership in the Sobolev space is equivalent to
Roughly, has derivatives in iff decays faster than . The non-periodic case on an interval like obeys the same dictionary with the Fourier coefficients replaced by Chebyshev coefficients under : the substitution turns Chebyshev expansions on into Fourier cosine expansions on , and the two regularity-decay stories are the same. Either way: analytic-on-a-strip geometric decay, algebraic decay, jump no decay.
Why this is universal¶
The uncertainty principle is not a quirk of Chebyshev series. It is the same duality behind every modern lossy compressor: JPEG quantises a block-wise DCT of the image and throws away the small high-frequency coefficients that smooth regions produce few of; MP3 does the same to audio after a psychoacoustic reweighting; MP4/H.264 transforms blocks of video frames the same way. In each case, “smoothness” of the signal (continuous skin tones, sustained tones, slowly-moving scenes) is what makes the DCT spectrum sparse, and sparse spectra are what compress.
A close relative is the SVD (and its statistical cousin PCA). Instead of fixing the basis a priori (a DCT, Chebyshev, or Fourier basis), SVD learns the optimal basis for a given matrix or data set. The singular values then play the role of the coefficients, and for smooth data (slowly-varying images, correlated measurements) they decay fast so a low-rank truncation captures most of the information. The principle is the same: smooth data has a short tail in some basis, and that tail is what compression throws away. SVD differs from JPEG/MP3 only in that the basis is data-adapted rather than fixed.
The same duality also underlies the Nyquist sampling theorem for band-limited signals and adaptive mesh refinement in FEM, where refinement is concentrated on the regions where the solution lacks smoothness. Approximation, compression, and sampling are three faces of the same theorem.
The rest of the chapter turns this compression picture into concrete error bounds (Theorem 3, Corollary 1) and an adaptive algorithm (Algorithm 1) that realises them without any a priori knowledge of ’s regularity.
The Approximation Error¶
Theorem 3 (Uniform error bound for the Chebyshev projection)
If the Chebyshev series of converges uniformly on , then the Chebyshev projection from Definition 4 satisfies
Proof 2
and on . Applying the triangle inequality term by term gives the bound.
Applying the decay theorems to the tail yields rates.
Corollary 1 (Convergence rates)
Proof 3
Convergence in action¶
Before bridging projection to interpolant, check whether the predicted rate actually shows up on a concrete example. Take , analytic with poles at and Bernstein parameter . The corollary predicts for the projection. Below we plot and its Chebyshev interpolant at two values of , shading , and ask whether the interpolant shows the same rate.
def cheb_eval(c, xx):
"""Clenshaw's algorithm: evaluate sum_k c_k T_k(xx) backward."""
b1 = np.zeros_like(xx)
b2 = np.zeros_like(xx)
two_x = 2 * xx
for k in range(len(c) - 1, 0, -1):
b1, b2 = c[k] + two_x * b1 - b2, b1
return c[0] + xx * b1 - b2
f = lambda x: 1/(1 + 25*x**2)
xx = np.linspace(-1, 1, 2000)
fig, axes = plt.subplots(1, 2, figsize=(10, 4))
for ax, n in zip(axes, [8, 16]):
xn = chebpts(n)
c = vals2coeffs(f(xn))
pn = cheb_eval(c, xx)
fx = f(xx)
ax.plot(xx, fx, 'k', lw=2, label=r'$f$')
ax.plot(xx, pn, 'C0', lw=1.2, label=f'$p_{{{n}}}$')
ax.fill_between(xx, fx, pn, color='C3', alpha=0.3,
label=r'$|f - p_n|$')
ax.plot(xn, f(xn), 'ko', ms=3)
err = np.max(np.abs(fx - pn))
ax.set_title(f'$n = {n}$, max error $= {err:.2e}$')
ax.set_xlabel('$x$')
ax.legend(fontsize=9, loc='upper right')
plt.tight_layout(); plt.show()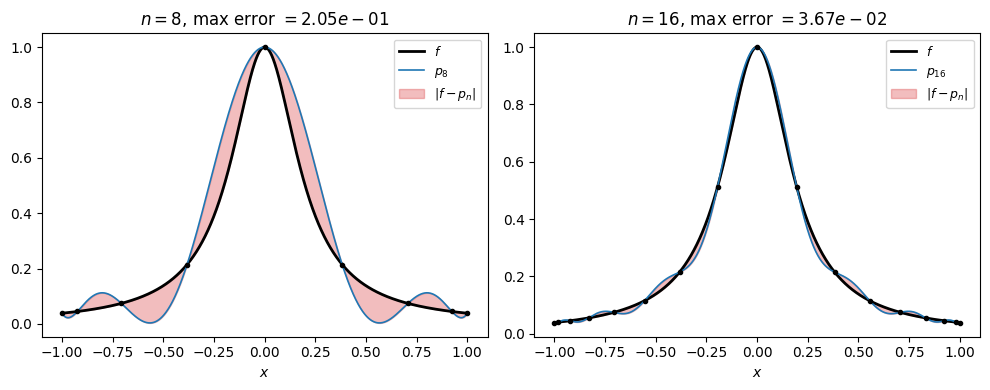
Doubling from 8 to 16 shrinks the maximum error by roughly a factor of , matching the projection-rate prediction. The interpolant tracks the projection rate very closely. We will explain why, through the Lebesgue constant, in the subsection after next.
The Gibbs Phenomenon¶
Before taking the interpolant story further, look at the other end of the regularity spectrum. Do we really need the bounded-variation hypothesis to get any decay at all? The sign function is the limiting case. It has bounded variation (one jump of height 2), so Theorem 1 applies with and gives
But the tail sum that bounds the uniform error,
diverges. The bound is useless, and that is not an artefact of our bounding: there really is no uniform convergence when has a jump. Near the discontinuity the truncated series exhibits a persistent overshoot whose magnitude does not shrink as . Only its width shrinks.
def cheb_interp_sign(xeval, n):
x = chebpts(n)
c = vals2coeffs(np.sign(x))
return cheb_eval(c, xeval)
xx = np.linspace(-0.5, 0.5, 4000)
fig, ax = plt.subplots(figsize=(7.5, 4.2))
for n, color in zip([16, 64, 256], ['C0', 'C1', 'C3']):
ax.plot(xx, cheb_interp_sign(xx, n), color=color, lw=1, label=f'$n = {n}$')
ax.plot([-0.5, 0, 0, 0.5], [-1, -1, 1, 1], 'k--', lw=1,
label=r'$\mathrm{sign}(x)$')
ax.axhline(1.1789, color='gray', ls=':', lw=1, alpha=0.7,
label=r'asymptotic peak $\approx 1.18$')
ax.set_xlabel('$x$'); ax.set_ylim(-1.4, 1.4)
ax.set_title('Gibbs phenomenon: overshoot persists, only narrows')
ax.legend(fontsize=9, loc='lower right'); plt.tight_layout(); plt.show()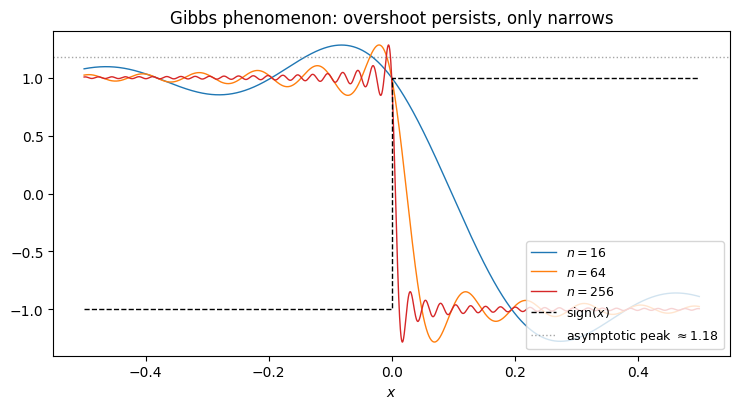
The peak value of the truncated series can be derived in closed form. The idea is standard: write the partial sum of via its Chebyshev (equivalently, Fourier) coefficients, differentiate to locate the first local maximum after the jump, and take . The maximum sits at , and substituting turns the partial sum into a Riemann integral:
where is the sine integral. The overshoot above the upper plateau (value 1) is , or of the total jump height 2. This Gibbs–Wilbraham constant is universal: it depends only on the existence of a jump, not on the specific function or its location. The effect was first described by Wilbraham (1848) and famously rediscovered by Gibbs in Nature (1898), a half-century apart. It is the same constant and the same phenomenon as for Fourier series, which the two problems are under .
The Sobolev picture sharpens the lesson. Membership in is equivalent to . For a function with this becomes , which converges iff . The jump function sits exactly on the Sobolev threshold , which is also the embedding boundary . Below that threshold a function cannot be continuous, so the partial sums cannot converge uniformly to it, and the persistent Gibbs overshoot is the geometric record of that failure.
Bounded variation is enough for pointwise convergence by the Dirichlet–Jordan theorem. For any BV function on the Chebyshev series converges at every point to
the average of the one-sided limits. At continuity points this is just ; at a jump it is the midpoint. For the series thus converges to 0 at and to elsewhere, everywhere pointwise. What fails is uniform convergence.
Remark 1 (Pointwise versus uniform)
Why is uniform stronger, and why doesn’t pointwise convergence rule out the Gibbs overshoot? The two notions differ in where the index is allowed to depend.
Pointwise: for every and every , there is an such that for all . The you need can grow as moves.
Uniform: for every , there is a single that works for every at once, so .
Gibbs is exactly what pointwise allows and uniform forbids. The overshoot has a fixed height , but its location slides toward the jump as grows (the peak sits at distance ). For any fixed , once is large enough the overshoot sits between and the jump rather than at , and approaches cleanly. So every fixed sees convergence: pointwise holds. But never falls below , because there is always some near 0 where the overshoot has moved to: uniform fails.
The bad is moving, and pointwise convergence lets that happen. Uniform convergence is the promise that no such moving pocket of error can persist.
Take-away. BV gives coefficient decay at rate and pointwise convergence, but not uniform convergence. If you must approximate discontinuous data, split the domain at the jumps and interpolate each smooth piece separately.
From projection to interpolant¶
The rates above control the projection , the truncated Chebyshev series. What we actually compute is the Chebyshev interpolant (the polynomial through at nodes), and the two agree only up to aliasing. To transfer rates from to we need one more ingredient.
Definition 2 (Lebesgue function and Lebesgue constant)
For interpolation nodes with Lagrange basis , the Lebesgue function is
and the Lebesgue constant is .
At we can see each individually and watch them combine into .
def lagrange_abs(j, nodes, xx):
xj = nodes[j]
out = np.ones_like(xx)
for i, xi in enumerate(nodes):
if i == j:
continue
out *= (xx - xi) / (xj - xi)
return np.abs(out)
m = 10
x_eq = np.linspace(-1, 1, m+1)
x_ch = np.cos(np.pi * np.arange(m+1) / m)
xx = np.linspace(-1, 1, 2000)
fig, axes = plt.subplots(1, 2, figsize=(10, 4), sharey=True)
for ax, nodes, title in zip(axes, [x_eq, x_ch], ['equispaced', 'Chebyshev']):
Lam = np.zeros_like(xx)
for j in range(len(nodes)):
lj = lagrange_abs(j, nodes, xx)
ax.plot(xx, lj, color='gray', lw=0.6, alpha=0.6)
Lam += lj
ax.plot(xx, Lam, color='C3', lw=2.0, label=r'$\Lambda_n(x)$')
ax.plot(nodes, np.zeros_like(nodes), 'ko', ms=4)
ax.set_title(f'{title}, $n = {m}$')
ax.set_xlabel('$x$')
ax.legend(loc='upper center')
axes[0].set_ylabel(r'$|\ell_j(x)|$ and $\Lambda_n(x)$')
plt.tight_layout(); plt.show()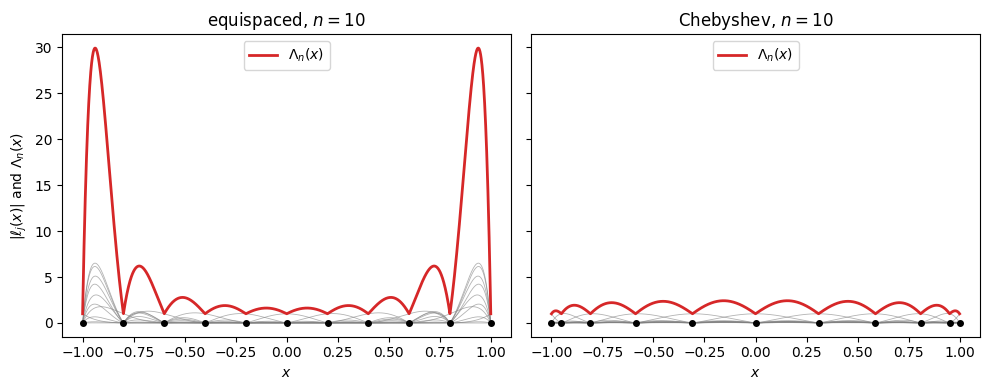
Grey curves are the individual ; the red envelope is their sum . On equispaced nodes the basis functions near the endpoints grow large, and their sum peaks sharply there. On Chebyshev nodes the basis functions stay bounded by roughly 1, and their sum stays close to 1 across the interval.
Theorem 4 (Near-best approximation)
Let interpolate at the nodes and denote the best polynomial approximation of degree . Then
The Lebesgue constant is the amplification factor between the best polynomial approximation of and the interpolant we can actually compute. Since is some polynomial of degree , . Chaining with the theorem,
The interpolation error splits into two factors:
Projection error , controlled by the coefficient decay theorems and hence by the regularity of .
Interpolation penalty , controlled by the node placement.
To see how the Lebesgue constant scales with , track the maximum of over a range of :
def lebesgue_func(xeval, nodes):
n = len(nodes)
out = np.zeros_like(xeval)
for j in range(n):
Lj = np.ones_like(xeval)
for i in range(n):
if i != j:
Lj *= (xeval - nodes[i]) / (nodes[j] - nodes[i])
out += np.abs(Lj)
return out
ns = np.arange(4, 41, 2)
L_eq, L_ch = [], []
for m in ns:
xe = np.linspace(-1, 1, m+1)
xc = np.cos(np.pi * np.arange(m+1) / m)
xx = np.linspace(-1, 1, 4000)
L_eq.append(lebesgue_func(xx, xe).max())
L_ch.append(lebesgue_func(xx, xc).max())
fig, ax = plt.subplots(figsize=(7.5, 4.2))
ax.semilogy(ns, L_eq, 'o-', label='equispaced')
ax.semilogy(ns, L_ch, 's-', label='Chebyshev')
ax.semilogy(ns, 2/np.pi * np.log(ns) + 1, 'k:', label=r'$\frac{2}{\pi}\log n$')
ax.set_xlabel('$n$'); ax.set_ylabel(r'$\Lambda_n$')
ax.set_title('Lebesgue constant: exponential vs logarithmic growth')
ax.legend(); plt.tight_layout(); plt.show()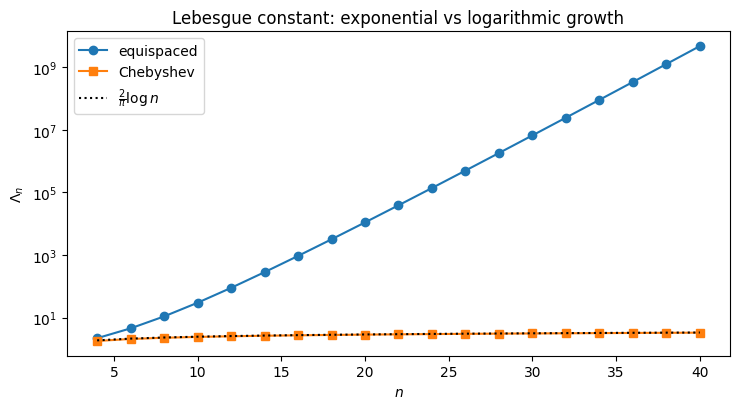
The asymptotic rates (Trefethen (2013)) are
No choice of interpolation nodes on can do better than ; the Chebyshev rate is optimal up to a constant. For equispaced nodes the interpolation penalty alone grows faster than any polynomial decay can compensate, which recovers the Runge picture: no matter how smooth is, fails to converge.
Choosing Adaptively¶
The decay theorems guarantee that at a rate controlled by the regularity of . In practice we do not want to set by hand. We want an algorithm that samples , reads off the coefficient tail, and returns the smallest for which truncation is already below tolerance. The following is the algorithm Chebfun uses, simplified.
Algorithm 1 (Adaptive Chebyshev truncation)
Input. Function on ; tolerance ; cap .
Output. Truncated coefficient vector with .
Set .
Sample at the Chebyshev nodes; compute by DCT.
Inspect the last of the coefficients, for .
If in that block is below : the tail has resolved. Find the smallest such that all lie below ; return .
Else double and return to step 2. If , report failure to resolve.
The termination test in step 4 is the operational form of the decay theorems. If is analytic or with , the eventually drop below any positive tolerance, so the loop terminates. If has a jump, decays like at best, and the tail never clears the tolerance. Non-termination is a correct diagnostic that the regularity hypothesis of Theorem 1 has failed.
Worked example: ¶
The function is entire and approaches over a short transition near the origin. It is smooth enough for adaptivity to succeed, steep enough that a small will not do.
def adaptive_cheb(f, tol=1e-12, Nmax=2**15):
N = 16
while N <= Nmax:
x = chebpts(N)
c = vals2coeffs(f(x))
tail_start = int(0.9 * N)
if np.max(np.abs(c[tail_start:])) < tol:
small = np.abs(c) < tol
M = N
while M > 0 and small[M]:
M -= 1
return N, M, c
N *= 2
raise RuntimeError('did not resolve within Nmax')
f = lambda x: np.tanh(20*x)
N, M, c = adaptive_cheb(f, tol=1e-12)
fig, ax = plt.subplots(figsize=(7.5, 4.2))
ax.semilogy(np.abs(c) + 1e-20, '.', ms=3, label=f'|c_k|, sampled at N={N}')
ax.axhline(1e-12, color='k', ls=':', label=r'tol $= 10^{-12}$')
ax.axvline(M, color='C3', ls='--', label=f'truncation M = {M}')
ax.set_xlabel('$k$'); ax.set_ylabel(r'$|c_k|$')
ax.set_title(r'Adaptive resolution of $\tanh(20 x)$')
ax.set_xlim(0, N); ax.set_ylim(1e-18, 5)
ax.legend(); plt.tight_layout(); plt.show()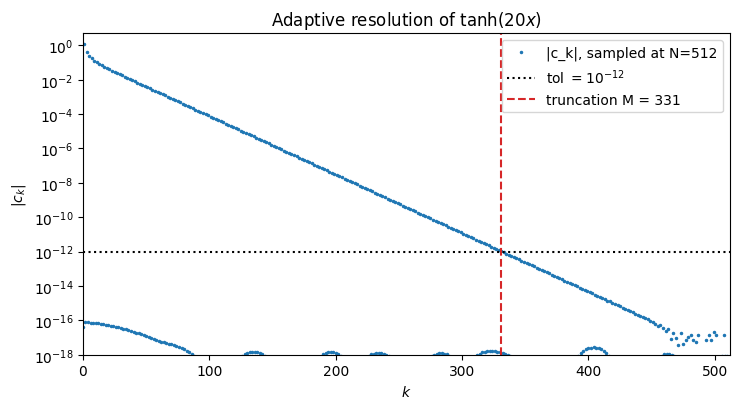
The loop doubles until the top of the coefficient spectrum sits below 10-12, then reports the first index at which the tail has flattened. The caller receives and a near-best polynomial approximant of automatically chosen degree.
- Trefethen, L. N. (2013). Approximation Theory and Approximation Practice. SIAM.