Runge’s divergence is a property of node placement, not of polynomial interpolation as such. Equispaced nodes leave the interpolating polynomial free to oscillate with exponentially growing amplitude near the endpoints. The Chebyshev nodes are the cosine images of equispaced angles on a semicircle. They cluster at the endpoints and cure the problem: with them, smooth functions are approximated geometrically. The Lebesgue constant quantifies the contrast. Equispaced nodes amplify errors by , Chebyshev nodes by .
Runge’s Phenomenon¶
Consider the function on . It is smooth on the real line. We interpolate it at equispaced nodes and plot the result for a few values of .
import numpy as np
import matplotlib.pyplot as plt
f = lambda x: 1/(1 + 25*x**2)
def bary_eval(xeval, x, fvals, w):
diff = xeval[:, None] - x[None, :]
at_node = np.isclose(diff, 0.0)
diff[at_node] = 1.0
terms = w / diff
out = (terms * fvals).sum(axis=1) / terms.sum(axis=1)
r, c = np.where(at_node)
out[r] = fvals[c]
return out
def equispaced_weights(x):
n = len(x)
w = np.ones(n)
for j in range(n):
for i in range(n):
if i != j:
w[j] /= (x[j] - x[i])
return w
xx = np.linspace(-1, 1, 1000)
ns = [6, 10, 14]
colors = ['C0', 'C1', 'C3']
fig, axes = plt.subplots(1, 3, figsize=(12, 4), sharey=True)
for ax, n, color in zip(axes, ns, colors):
xe = np.linspace(-1, 1, n+1)
fe = f(xe)
we = equispaced_weights(xe)
pe = bary_eval(xx, xe, fe, we)
ax.plot(xx, f(xx), 'k', lw=2, label=r'$f(x) = 1/(1+25x^2)$')
ax.plot(xx, pe, color=color, lw=1.2, label=f'$p_{{{n}}}$ (equispaced)')
ax.plot(xe, fe, 'o', color=color, ms=4)
ax.set_ylim(-0.5, 1.5)
ax.set_xlabel('$x$')
ax.set_title(f'$n = {n}$')
ax.legend(fontsize=9, loc='upper right')
fig.suptitle(r"Runge: equispaced interpolation diverges near $\pm 1$")
plt.tight_layout(); plt.show()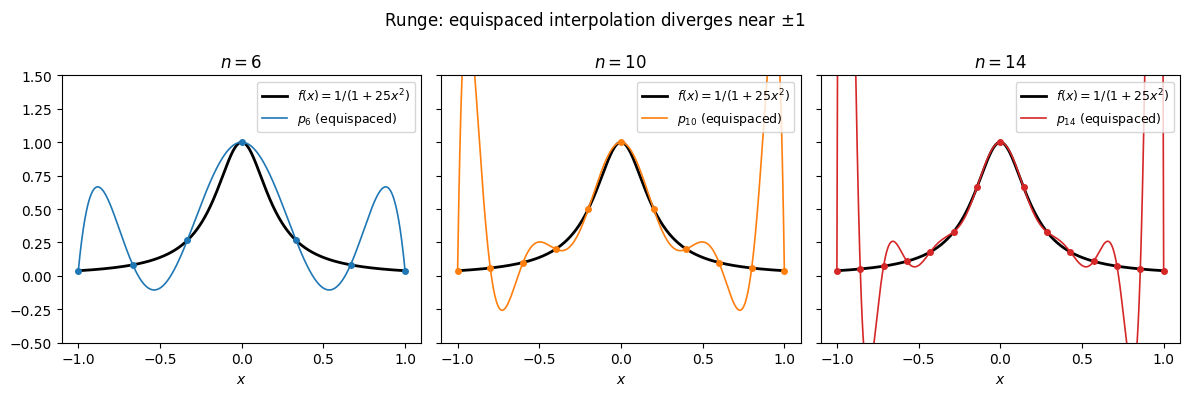
The interpolant passes through every node, but between nodes near the endpoints it oscillates with amplitude that grows without bound. The function is analytic on the whole real line. The divergence is entirely a property of the node placement.
A function is real-analytic at if its Taylor series about converges to in some neighborhood of . Analytic functions are smooth (infinitely differentiable) and are completely determined by their values on any open set. Polynomials, , , , and rational functions away from the zeros of are all analytic.
Being analytic on does not mean the Taylor series converges globally. The Runge function is analytic on all of , but its Taylor series about converges only for , the distance to the nearest complex pole at . That complex-plane picture is what actually controls polynomial approximation rates; we return to it in Regularity and Coefficient Decay.
Why does moving the nodes help? Polynomial interpolation on is really an angular problem in disguise. Under the change of variables , the endpoints correspond to , while the interior is compressed. Nodes that are equispaced in are badly unequal in , with the largest angular gaps sitting near . Those are exactly the gaps where the oscillations blow up.
Sampling uniformly in instead produces nodes that cluster at the endpoints. The standard choice is the Chebyshev nodes.
Chebyshev Nodes¶
Definition 1 (Chebyshev Nodes (of the second kind))
The Chebyshev points on are
Geometric origin¶
Place equispaced points on the upper unit semicircle and project them straight down to the -axis. Equispaced angles , so . That is the picture.
n = 12
theta = np.pi * np.arange(n+1) / n
x_ch = np.cos(theta)
fig, ax = plt.subplots(figsize=(7, 3.6))
phi = np.linspace(0, np.pi, 200)
ax.plot(np.cos(phi), np.sin(phi), 'k', lw=1)
ax.plot([-1, 1], [0, 0], 'k', lw=1)
ax.plot(x_ch, np.sin(theta), 'o', color='C0', ms=6, label='equispaced on circle')
for xc, yc in zip(x_ch, np.sin(theta)):
ax.plot([xc, xc], [0, yc], color='C0', lw=0.6, alpha=0.5)
ax.plot(x_ch, np.zeros_like(x_ch), 's', color='C3', ms=6, label='Chebyshev nodes')
ax.set_aspect('equal'); ax.axis('off'); ax.legend(loc='upper right')
ax.set_title('Chebyshev nodes are projections of equispaced points on the circle')
plt.tight_layout(); plt.show()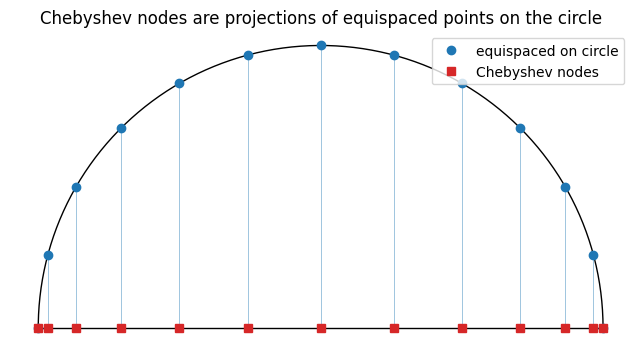
The clustering near is exactly what tames the endpoint instability seen in the Runge example. The optional final section on Lebesgue constants makes this precise.
Barycentric weights for free¶
The barycentric formula from Proposition 1 needs the weights . On Chebyshev nodes these collapse to a closed form (up to a common scale, which cancels in the second barycentric formula):
No precomputation is needed: just a sign flip and a halving at the endpoints. Evaluating at an arbitrary point is then one pass with no setup cost, which is what makes the barycentric formula on Chebyshev nodes the evaluator of choice.
Chebyshev polynomials and the recurrence¶
The Chebyshev nodes came from sampling uniformly in under . The natural basis for functions on the side is the Fourier cosine basis , the standard frequencies on a periodic interval. We ask: under , what do these basis functions look like on the side?
Check the first few by expanding with angle-addition:
: .
: .
: .
: .
Each one is a polynomial in , of degree exactly . This is not an accident.
Definition 2 (Chebyshev polynomial of the first kind)
The -th Chebyshev polynomial of the first kind is the polynomial characterised by
The definition is only useful if such a polynomial exists for every . The recurrence makes this explicit.
Proposition 1 (Three-term recurrence)
Proof 1
The product-to-sum identity rearranges to
Setting and substituting converts the right-hand side to , which must therefore equal . The base cases and are immediate from the definition, and induction carries polynomiality and the degree forward.
The first few Chebyshev polynomials are therefore
and the pattern continues. Under they are literally the Fourier cosine basis, which means they inherit a lot of nice properties for free: bounded by 1 on , extrema there with alternating signs , orthogonal under the weighted inner product we will see below. The Chebyshev polynomials are just a re-encoding of in that natural frequency basis, related to the monomials by an upper-triangular change of basis.
The Chebyshev Series¶
So far the Chebyshev polynomials have appeared as a tool for placing nodes. They are also a basis of . More importantly, the full family is an orthogonal system on under a natural weighted inner product, and suffices to represent any Lipschitz function on as a convergent series.
Definition 3 (Chebyshev series)
Definition 4 (Chebyshev projection)
The Chebyshev projection of degree of is the truncated series
where the are the Chebyshev coefficients of Definition 3.
The Chebyshev projection defined above is not the same polynomial as the Chebyshev interpolant , the polynomial of degree that passes through at the Chebyshev nodes. The two agree up to an aliasing correction that decays at the same rate as the Chebyshev coefficients themselves, so for convergence purposes we treat them interchangeably. But in practice we always compute the interpolant (via the DCT below), not the projection, because the interpolant only needs nodal samples of , whereas the projection needs the true integral coefficients .
If you have seen Fourier series, the substitution turns the Chebyshev series of on into the Fourier cosine series of on . Statements about Fourier series (decay rates, Gibbs phenomenon, Parseval) carry over verbatim.
Computing the Coefficients¶
We rarely have a closed form for . Instead we sample at the Chebyshev nodes and use a discrete formula. Two facts make this efficient: discrete orthogonality of the at those nodes, and the cosine structure that lets the FFT do the work.
The values↔coefficients matrix¶
Just as the monomial basis produced the Vandermonde system , the Chebyshev basis at the Chebyshev nodes produces its own values↔coefficients map. With and , the equations become
Compare to the Vandermonde matrix from Polynomial Interpolation: Values and Coefficients: same layout (rows = nodes, columns = basis functions), but cosines in place of monomial powers. That change of basis is what fixes the ill-conditioning. Here independent of , versus that exploded exponentially and broke double precision by . And inverting is free: the FFT applies in . The two lemmas below make this precise.
Remark 1 (Where the comes from)
The matrix satisfies with , the discrete orthogonality relation for cosines. The columns of are mutually orthogonal, but the endpoint columns have norm and the interior ones have norm , differing by a factor of . Rescaling by gives a genuinely orthogonal with condition number 1, so the full .
Lemma 1 (Discrete coefficient formula)
Proof 2
The satisfy a discrete orthogonality relation at the Chebyshev nodes:
This follows from and the standard discrete orthogonality of cosines. Imposing and applying the orthogonality relation isolates as stated. If the interpolant is , so .
For functions the discrete coefficients approximate the true to within an aliasing error that decays at the same rate as itself, so for our purposes we treat the two interchangeably and write for both.
Lemma 2 (DCT computation)
The discrete coefficients of Lemma 1 are the output of the type-I Discrete Cosine Transform of the value vector . Equivalently, they are the result of solving . The Cooley–Tukey FFT algorithm Cooley & Tukey, 1965 carries out this basis change in operations.
The two lemmas together give the practical picture. Starting from nodal samples of a smooth , one DCT performs the basis change from values to Chebyshev coefficients, and the inverse DCT reconstructs the values. Each costs when computed via an FFT. This acceleration is the reason spectral methods are practical, and we use it freely in the integration and differentiation sections that follow.
Evaluating at Arbitrary Points¶
The DCT recovers at the Chebyshev nodes themselves, but we often want at some other . Given the coefficients , we need to evaluate
A naïve approach builds via the three-term recurrence and accumulates the sum, which is work. Clenshaw’s algorithm does the same in but runs the recurrence backward on the coefficients, never forming the intermediate values. The backward sweep is backward-stable on , which is why libraries implement it as the standard evaluator.
Algorithm 1 (Clenshaw’s algorithm)
Proof 3
A Classical Aside: The Minimax Property¶
The Chebyshev polynomial has a beautiful classical extremum: among all monic polynomials of degree on , the rescaled polynomial has the smallest sup-norm, equal to . This is the minimax or equioscillation property. Applied to the node polynomial of interpolation nodes, it means the zeros of , the first-kind Chebyshev nodes, are the choice that minimises . The second-kind nodes used throughout this chapter are close cousins with the same asymptotic behaviour. None of this is load-bearing for the convergence rates; it is a standalone classical fact. See Trefethen (2013), Ch. 3 for the proof and context.
- Cooley, J. W., & Tukey, J. W. (1965). An algorithm for the machine calculation of complex Fourier series. Mathematics of Computation, 19(90), 297–301.
- Trefethen, L. N. (2013). Approximation Theory and Approximation Practice. SIAM.