This section and the next (§Barron’s Theorem) cover material beyond the core MATH 551 syllabus. They extend the deterministic 1D approximation theory to the high-dimensional setting, where neural networks are the practitioner’s tool. The content is included for interested students; nothing later in the course depends on it.
A one-hidden-layer neural network is a basis expansion in ridge functions . Cybenko (1989) and Hornik (1991) showed this basis is dense in , just like polynomials: every continuous target can be approximated to any tolerance, in any dimension. Density is the qualitative result. It says nothing about how many ridges are needed; that is a separate question, and the one where dimension actually bites. We answer it on the next two pages.
Why we care: functions on in practice¶
The input is just a list of numbers, and that covers most of the real-world objects we want to compute with:
Images: pixel intensities, to 106.
Text: word or sentence embeddings, to 104.
Molecules: atomic positions, charges, and types, for small molecules.
Games and control systems: the state of a board, robot, or vehicle at one moment in time.
Models: the parameters of a physical or financial model whose outcome we want to predict.
The function (or ) we want is then “image class label”, “sentence translation”, “molecule binding energy”, “board state best move”, “model parameters option price”. None of these are available in closed form, and the input dimensions are firmly outside what tensor-product Chebyshev or any other deterministic basis can handle. The next page makes that obstacle quantitative (the curse of dimensionality) and shows under what hypothesis a neural network gets around it (Barron’s theorem). The current page builds the basis (ridge functions), shows it can represent any continuous target (universal approximation), and demonstrates a 1D failure mode that flips when is large.
A neural network as a basis expansion¶
A one-hidden-layer network is
with , weights , biases , output coefficients , and a fixed non-linearity . Stacking the as rows of a matrix gives the matrix form
with acting elementwise.
Each term is a ridge function: a 1D function depending on only through , extruded along the directions perpendicular to . A network is a sum of such ridges; controls the direction, shifts it, scales it.
Compare with a Chebyshev expansion . Both are linear combinations of basis functions. The Chebyshev basis is fixed; the ridge basis is parameterised by that we can choose.
A 1D ridge network: evaluation, differentiation, integration¶
In one variable a ridge is just a shifted, scaled copy of : with . The basis is parameterised but each basis function is something we can draw on a single axis. Before doing any algebra, look at it.
What a ridge basis looks like¶
Three panels. The left shows three single ridges with different . The slope at the inflection point is for , so controls how fast the ridge transitions from one saturation level to the other; the sign of flips left and right; shifts the inflection point to . The middle panel overlays a few , dashed unscaled and solid scaled, to show how rescales each individual ridge. The right panel adds them up and overlays a target.
import numpy as np
import matplotlib.pyplot as plt
sigma = np.tanh
xs = np.linspace(-2, 2, 400)
fig, axes = plt.subplots(1, 3, figsize=(11, 3.2))
# Panel 1: three single ridges
ax = axes[0]
for w, b, label in [(1, 0, r"$w=1,\ b=0$"),
(4, 0, r"$w=4,\ b=0$"),
(-2, 1, r"$w=-2,\ b=1$")]:
ax.plot(xs, sigma(w * xs + b), label=label)
ax.set_title(r"Single ridges $\sigma(wx+b)$")
ax.legend(fontsize=8, loc="lower right")
ax.set_xlabel(r"$x$"); ax.grid(alpha=0.3)
# Panel 2: scaled vs unscaled
ax = axes[1]
params = [(3, -1, 1.0), (-2, 0.5, -0.7), (1.5, 1, 1.3)]
for w, b, a in params:
ax.plot(xs, sigma(w * xs + b), '--', alpha=0.45)
ax.plot(xs, a * sigma(w * xs + b), '-')
ax.set_title(r"Scaled ridges $a_k\,\sigma(w_k x+b_k)$")
ax.set_xlabel(r"$x$"); ax.grid(alpha=0.3)
# Panel 3: sum vs target
ax = axes[2]
target = lambda t: np.sin(2 * np.pi * t) * np.exp(-0.5 * t**2)
rng = np.random.default_rng(0)
n = 30
ws = rng.normal(scale=4, size=n)
bs = rng.uniform(-3, 3, size=n)
V = sigma(np.outer(xs, ws) + bs)
y = target(xs)
a, *_ = np.linalg.lstsq(V, y, rcond=None)
ax.plot(xs, y, 'k-', lw=2, label="target")
ax.plot(xs, V @ a, '--', lw=1.5, label=f"sum, $n={n}$")
ax.set_title(r"Sum $\sum_k a_k\,\sigma(w_k x+b_k)$")
ax.legend(fontsize=8); ax.set_xlabel(r"$x$"); ax.grid(alpha=0.3)
plt.tight_layout()
plt.show()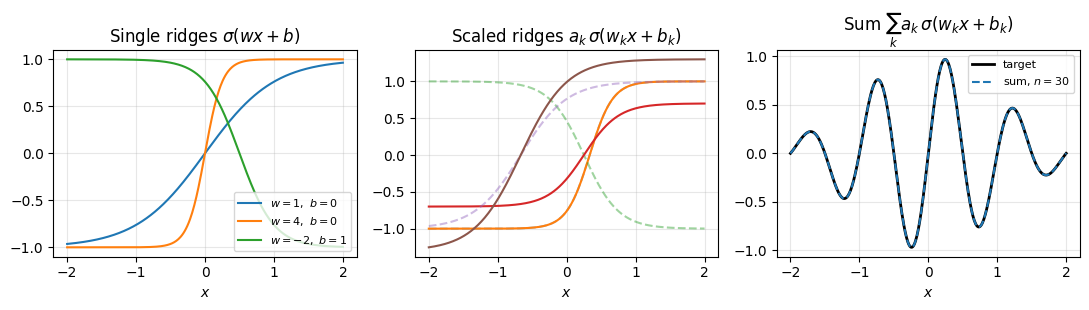
The takeaway: each ridge contributes one bend, localised to a region of width around . Outside that region the ridge is essentially constant and adds nothing. Contrast with Chebyshev, where every oscillates across the entire interval . Ridges are local, polynomials are global. This single fact drives the difference in behaviour in high dimensions: a -variable ridge is a 1D bump pulled along flat directions, so its cost does not multiply with , while a tensor-product basis of global polynomials does.
Random features: the linear case¶
The simplest way to fix is to draw them randomly from a probability distribution, for instance and . Once drawn, the weights are frozen and only varies; every operation becomes linear in the coefficient vector , and the ridge basis is a fixed basis like . This is the random-features view of a one-hidden-layer network: no training, no gradient descent, just a random draw followed by a single linear solve.
The random draw raises two questions we defer to the next page: which distribution to sample from (Fourier inversion picks out the right one) and what does random sampling buy quantitatively (the draw is a Monte Carlo sample, with the dimension-free rate). Both are answered in §Barron. For now any concrete distribution suffices to demonstrate the construction.
We come back to the trained case at the end, where the random draw is replaced by gradient descent on .
Evaluation¶
at a point. For a batch , this is with . Cost , the same shape as Chebyshev’s value-from-coefficient map.
Differentiation¶
, so
The coefficient map is with , expressed in the related basis . Like Chebyshev: differentiation maps to a different family, and a recurrence converts back. For ridges we evaluate in the -basis directly.
Integration¶
If then . For , . The definite integral is
A linear functional with precomputed moments, identical in shape to the Chebyshev integration construction.
Fitting¶
Given data and the frozen weights from above, the coefficients minimise the empirical loss
a linear least squares problem in . With Chebyshev nodes for and the -basis the matrix is structured and a DCT solves it in . With random ridges no such structure, but the standard QR-based least-squares solver from §Least Squares is still cheap, and there is no non-convex search.
The empirical loss is itself a Monte Carlo estimator of the population loss
provided the data points are drawn iid from ; is unbiased for and its standard deviation around decays as (see the Monte Carlo notebook for the standard rate). So the random-features network is doing two things at once: sampling weights, and estimating an integral (the loss) from samples. The first piece is what §Barron makes principled.
The trained case¶
If we let vary too, the loss
is non-convex. To see why, recall the basis matrix from the fitting section above: is the -th basis function evaluated at the -th data point. With frozen, is a fixed matrix and is quadratic (hence convex) in . Once we let vary, depends nonlinearly on through , the loss loses its quadratic structure, and many local minima appear. There is no closed-form solver. We descend.
Stochastic gradient descent¶
Vanilla gradient descent updates with and . Each step costs work; for in the millions this is unaffordable.
Stochastic gradient descent (SGD) replaces the full sum with a random mini-batch at each step (sizes 32 to 128 are typical):
Per-step cost drops to . The mini-batch gradient is a Monte Carlo estimator of the full-batch gradient: unbiased, with variance . So in expectation each step does what gradient descent would; in any individual step the direction is noisy. In practice the step size is adapted per parameter using moving averages of and ; this is Adam, the standard default.
The full training loop:
Algorithm 1 (SGD training of a one-hidden-layer ridge network)
Inputs: initial parameters , learning rate , mini-batch size , dataset .
For :
Sample mini-batch uniformly at random (without replacement within an epoch).
Forward pass: evaluate for .
Loss: .
Backward pass: by chain rule.
Step: .
Stop when validation loss plateaus.
The “backward pass” step is just calculus: differentiate the loss with respect to each parameter. For a one-hidden-layer ridge network everything is fully explicit, which makes the training loop entirely concrete. For deeper networks the same chain-rule pattern is what backpropagation automates.
Let be the residual at sample , and . Differentiating:
The mini-batch gradient is the average of these over . Libraries (PyTorch, JAX) compute these automatically by reverse-mode automatic differentiation, but for a one-layer net you can write them by hand and verify.
The universal approximation theorem¶
The 1D story above shows ridges are a basis we can compute with: we can evaluate, differentiate, integrate, and fit, exactly as we did with . The first question to settle, before any quantitative rate, is whether this basis is flexible enough to represent every continuous function. That is the density question, and is what universal approximation answers.
Stone–Weierstrass already gives polynomial density in for compact , so “any continuous function in any dimension is approximable by polynomials” was a solved problem. Cybenko (1989) and Hornik (1991) added that ridge functions are also dense, under a hypothesis on called discriminatory.
Definition 1 (Discriminatory function)
A function is discriminatory on a compact if the only signed regular Borel measure on satisfying
is the zero measure .
The condition says: no signed measure can be invisible to every ridge function with activation . Equivalently, the closed linear span of in has no non-trivial annihilator, which by Hahn–Banach means the span is dense.
Theorem 1 (Universal Approximation (Cybenko 1989, Hornik 1991))
Let be continuous and discriminatory on a compact . For every continuous and every there is a width and parameters with
where .
A self-contained proof (Hahn–Banach plus a Fourier argument that continuous sigmoidal activations are discriminatory) is on this companion site for MATH 725. The two activations that dominate in practice both satisfy the hypothesis:
tanh / sigmoid: continuous sigmoidal (, ), discriminatory by Cybenko’s Lemma 1. Bounded and smooth, gradients vanish in the saturation regions.
ReLU, : discriminatory under Hornik’s extension, which only requires to be non-polynomial. Piecewise linear, unbounded, cheap; the modern default.
A first experiment: fitting ¶
Train a width-20 network with on over
. After 2000 Adam steps the network reaches
pointwise error. The adaptive Chebyshev chebfit_adaptive from
A Chebyshev Toolbox: Doing Linear Algebra with Functions reaches machine precision on
the same function with about 20 coefficients, in one DCT. Both get
arbitrarily close to ; the network needs thousands of
gradient steps and still plateaus at 10-2. In 1D the network is
strictly worse than what we already have. The picture flips in high
. Demo 1 of the companion
notebook.
§Barron’s Theorem and the Curse of Dimensionality: the obstacle (every fixed basis costs in dimensions), the integral representation of that turns this around, and the dimension-free rate that drops out.